
Introduktion till Ensembeltekniker
Ensemble learning är en teknik inom maskininlärning som tar hjälp av flera basmodeller och kombinerar deras output för att producera en optimerad modell. Denna typ av maskininlärningsalgoritm hjälper till att förbättra modellens totala prestanda. Här är den basmodell som oftast används beslutsklassificeringen. Ett beslutsträd fungerar i princip på flera regler och ger en prediktiv utgång, där reglerna är noderna och deras beslut kommer att vara deras barn och bladnoderna kommer att utgöra det ultimata beslutet. Som visas i exemplet på ett beslutsträd.
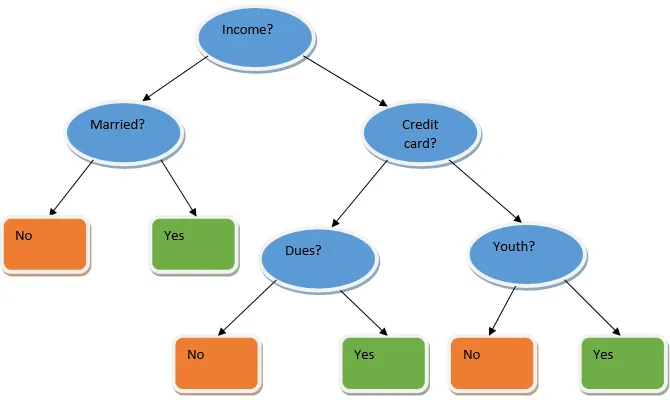
Ovanstående beslutsträd talar i princip om en person / kund kan få ett lån eller inte. En av reglerna för låneberättigande ja är att om (inkomst = Ja && Gift = Nej) Då är Lån = Ja så det här är hur en beslutsträdklassificerare fungerar. Vi kommer att integrera dessa klassificerare som en multipelbasmodell och kombinera deras utgång för att bygga en optimal prediktiv modell. Figur 1.b visar den övergripande bilden av en ensembleinlärningsalgoritm.
Typer av ensembletekniker
Olika typer av ensembler, men vårt huvudsakliga fokus kommer att ligga på nedanstående två typer:
- Säckväv
- öka
Dessa metoder hjälper till att minska variansen och förspänningen i en maskininlärningsmodell. Låt oss nu försöka förstå vad som är partiskhet och varians. Bias är ett fel som uppstår på grund av felaktiga antaganden i vår algoritm; en hög förspänning indikerar att vår modell är för enkel / underfit. Varians är det fel som orsakas på grund av modellens känslighet för mycket små fluktuationer i datauppsättningen; en hög varians indikerar att vår modell är mycket komplex / överfit. En idealisk ML-modell borde ha en korrekt balans mellan förspänning och varians.
Bootstrap Aggregating / Bagging
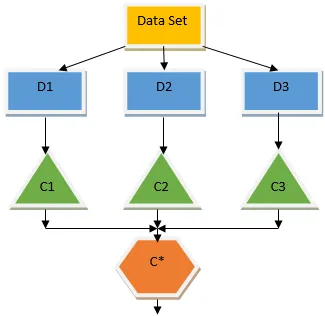
Bagging är en ensemble-teknik som hjälper till att minska variationen i vår modell och därmed undviker övermontering. Bagging är ett exempel på den parallella inlärningsalgoritmen. Påsar fungerar baserat på två principer.
- Bootstrapping: Från den ursprungliga datauppsättningen beaktas olika provpopulationer med ersättning.
- Sammanställning: Medelvärde för resultaten från alla klassificerare och tillhandahållande av en enda utgång, för detta använder den majoritetsröstningen vid klassificering och medelvärde för regressionsproblemet. En av de berömda maskininlärningsalgoritmerna som använder begreppet bagging är en slumpmässig skog.
Slumpmässig skog
I slumpmässig skog från det slumpmässiga provet som dras ut från befolkningen med ersättning och en delmängd av funktioner väljs från uppsättningen av alla funktioner som ett beslutsträd byggs. Från dessa delmängder av funktioner väljs vilken funktion som har den bästa delningen som roten för beslutsträdet. Funktionsdelmängden måste väljas slumpmässigt till varje pris, annars kommer vi att producera endast korrelerad tress och modellens varians kommer inte att förbättras.
Nu har vi byggt vår modell med prover tagna från populationen, frågan är hur validerar vi modellen? Eftersom vi överväger proverna med ersättning, kommer alla prover därför inte att beaktas och en del av det kommer inte att ingå i någon påse, dessa kallas ur påseprover. Vi kan validera vår modell med denna OOB (ur påsen) prover. De viktiga parametrarna som ska beaktas i en slumpmässig skog är antalet prover och antalet träd. Låt oss betrakta 'm' som delmängden av funktioner och 'p' är den fulla uppsättningen funktioner, nu som en tumregel är det alltid idealiskt att välja
- m as√ och en minsta nodstorlek som 1 för ett klassificeringsproblem.
- m som P / 3 och minsta nodstorlek till 5 för ett regressionsproblem.
M och p bör behandlas som inställningsparametrar när vi hanterar ett praktiskt problem. Utbildningen kan avslutas när OOB-felet stabiliserats. En nackdel med den slumpmässiga skogen är att när vi har 100 funktioner i vår datauppsättning och bara ett par funktioner är viktiga så kommer denna algoritm att fungera dåligt.
öka
Boosting är en sekventiell inlärningsalgoritm som hjälper till att minska partiskhet i vår modell och varians i vissa fall av övervakat lärande. Det hjälper också till att konvertera svaga elever till starka elever. Boosting fungerar på principen att placera de svaga eleverna i följd och det tilldelar en vikt till varje datapunkt efter varje omgång; mer vikt tilldelas den felklassificerade datapunkten i föregående omgång. Denna sekventiellt viktade metod för att utbilda vår datauppsättning är den viktigaste skillnaden än den för påsar.
Fig. 3 visar den allmänna metoden för att öka
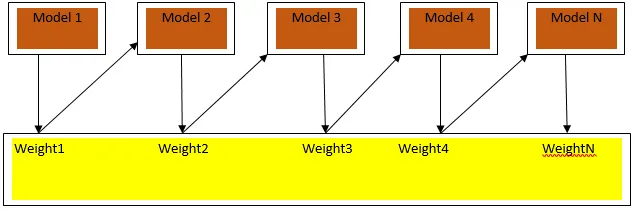
De slutliga förutsägelserna kombineras baserat på vägd majoritetsröstning vid klassificering och vägd summa för regression. Den mest använda boostingalgoritmen är adaptiv boosting (Adaboost).
Anpassningsförstärkning
Stegen som är involverade i Adaboost-algoritmen är följande:
- För de givna n datapunkterna definierar vi målgruppen och initialiserar alla vikterna till 1 / n.
- Vi anpassar klassificerarna till datauppsättningen och vi väljer klassificeringen med det minst vägda klassificeringsfelet
- Vi tilldelar vikter för klassificeraren med en tumregel baserad på noggrannhet, om noggrannheten är mer än 50% är vikten positiv och vice versa.
- Vi uppdaterar klassificeringarnas vikter i slutet av iterationen; uppdaterar vi mer vikt för den felklassificerade punkten så att vi i nästa iteration klassificerar den korrekt.
- Efter all iterationen får vi det slutliga förutsägelseresultatet baserat på majoritetsröstningen / det vägda genomsnittet.
Adaboosting arbetar effektivt med svaga (mindre komplexa) elever och med klassificerare med hög förspänning. De största fördelarna med Adaboosting är att det är snabbt, det finns inga inställningsparametrar som liknar fallet med påsar och vi gör inga antaganden för svaga elever. Denna teknik misslyckas med att ge ett exakt resultat när
- Det finns fler outliers i våra data.
- Datauppsättningen är otillräcklig.
- De svaga eleverna är mycket komplexa.
De är också mottagliga för brus. De beslutsträd som produceras som ett resultat av förstärkning kommer att ha begränsat djup och hög noggrannhet.
Slutsats
Ensembeltekniker används ofta för att förbättra modellens noggrannhet; vi måste bestämma vilken teknik vi ska använda utifrån vår datauppsättning. Men dessa tekniker föredras inte i vissa fall där tolkbarhet är av betydelse, eftersom vi tappar tolkbarhet till bekostnad av prestandaförbättring. Dessa har enorm betydelse inom hälso- och sjukvårdssektorn där en liten förbättring av prestandan är mycket värdefull.
Rekommenderade artiklar
Detta är en guide till Ensembeltekniker. Här diskuterar vi introduktionen och två huvudtyper av ensembletekniker. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer-
- Steganografitekniker
- Maskininlärningstekniker
- Team Building Techniques
- Data Science Algoritms
- Mest använda tekniker för lärande av ensemble