

Översikt över Kafka-applikationer
Ett av de trendfält inom IT-branschen är Big Data, där företaget hanterar en stor mängd kunddata och erhåller användbar insikt som hjälper deras verksamhet och ger kunderna bättre service. En av utmaningarna är att hantera och överföra dessa stora mängder data från ena änden till en annan för analys eller bearbetning, det är här som Kafka (ett pålitligt meddelandesystem) kommer in i spelet, vilket hjälper till att samla in och transportera en enorm datamängd i realtid. Kafka är designad för distribuerade system med hög kapacitet och passar bra för storskaliga meddelandebehandlingsapplikationer. Kafka stöder många av dagens bästa kommersiella och industriella applikationer. Kafka-yrkesverksamma har starka kunskaper och praktisk kunskap.
I den här artikeln kommer vi att lära oss om Kafka, dess funktioner, använda fall och förstå några anmärkningsvärda applikationer där den används.
Vad är Kafka?
Apache Kafka utvecklades på LinkedIn och blev senare ett open-source Apache-projekt. Apache Kafka är ett snabbt, feltolerant, skalbart och distribuerat meddelandesystem som möjliggör kommunikation mellan två enheter, dvs mellan producenter (meddelandets generator) och konsumenter (mottagare av meddelandet) med hjälp av meddelandebaserade ämnen och ger en plattform för att hantera alla dataströmmarna i realtid.
Funktionerna som gör Apache Kafka bättre än andra meddelandesystem och som är tillämpliga på realtidssystem är dess höga tillgänglighet, omedelbara, automatiska återställning från nodfel och stöder meddelandeleverans med låg latens. Dessa funktioner i Apache Kafka hjälper till att integrera det med storskaliga datasystem och gör det till en idealisk komponent för kommunikation. 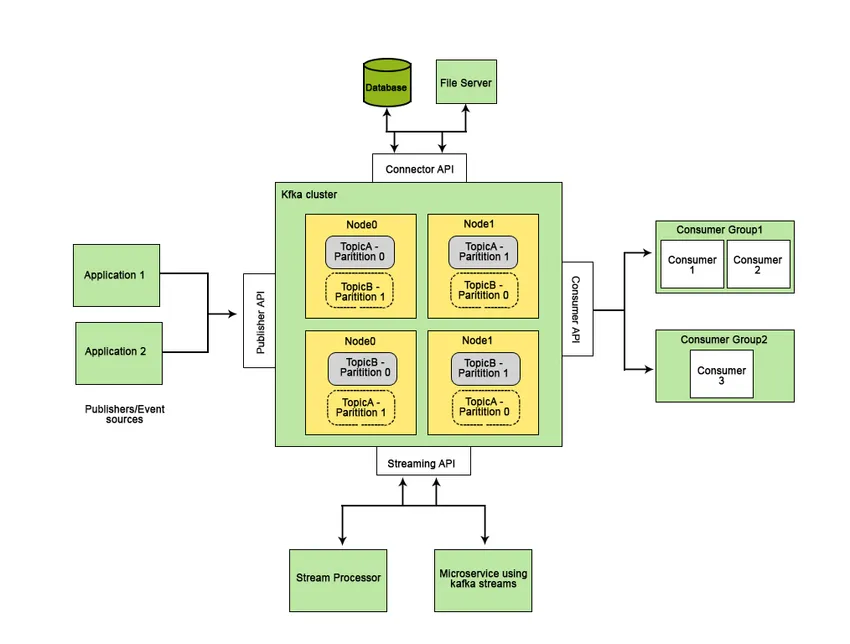
Topp Kafka-applikationer
I det här avsnittet av artikeln kommer vi att se några populära och omfattande implementerade fall och se en verklig implementering av Kafka.
Verklighetsapplikationer
1. Twitter: Streambehandlingsaktivitet
Twitter är en plattform för socialt nätverk som använder Storm-Kafka (öppen källkod för strömbearbetning) som en del av deras strömbehandlingsinfrastruktur, där inputdata (tweets) konsumeras för aggregering, transformationer och berikning för ytterligare konsumtion eller uppföljning bearbetningsaktiviteter.
2. LinkedIn: Stream Processing & Metrics
LinkedIn använder Kafka för att strömma data och för operationell metrisk aktivitet. LinkedIn använder Kafka för sina ytterligare funktioner som Newsfeed för att konsumera meddelanden och utföra analys av de mottagna uppgifterna.
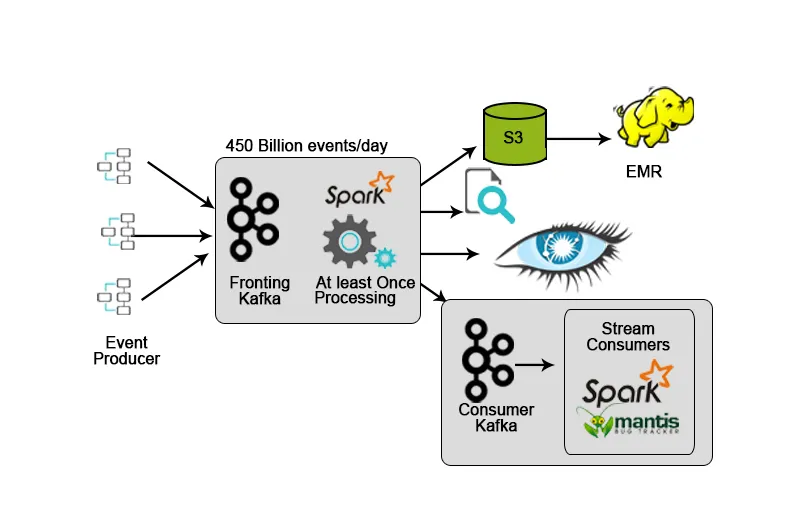
3. Netflix: Realtidsövervakning och strömbearbetning
Netflix har sitt eget intagningsramverk som dumpar inmatningsdata i AWS S3 och använder Hadoop för att köra analys av videoströmmar, UI-aktiviteter, händelser för att förbättra användarupplevelsen och Kafka för intag av data i realtid via API: er.
4. Hotstar: Streambehandling
Hotstar introducerade sin egen plattform för datahantering - Bifrost där Kafka används för dataströmning, övervakning och målspårning. På grund av dess skalbarhet, tillgänglighet och kapacitet med låg latens var Kafka ett idealiskt val att hantera de data som hotstar-plattformen genererar dagligen eller vid något speciellt tillfälle (direktuppspelning av konserter eller någon live sportmatch etc.) där datamängden ökar avsevärt.
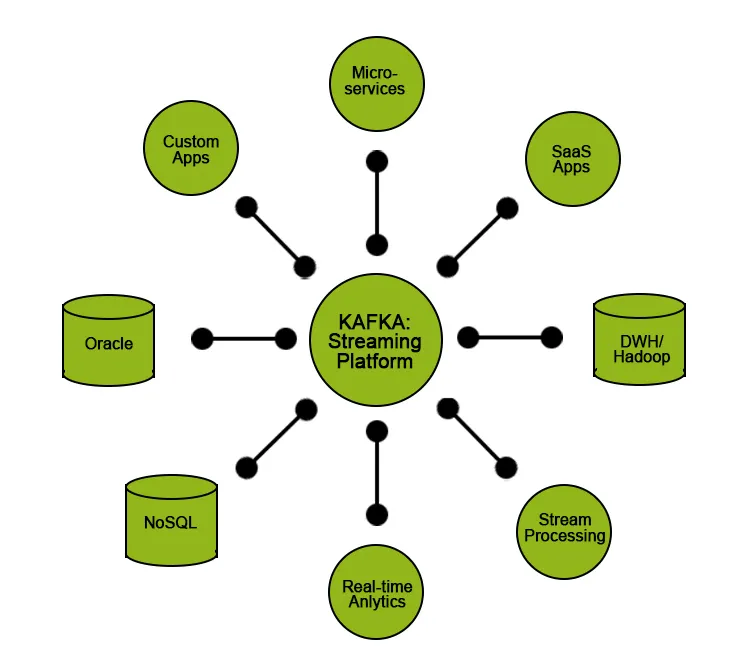
Apache Kafka används för det mesta som en byggsten för att utveckla strömningsdataarkitektur. Den här typen av arkitektur används i applikationer som en samling av produkt- / serverloggar, analys av klickström och härledning av information från maskingenererade data.
Men tillsammans med Kafka måste vi använda ytterligare resurser eller verktyg för att konvertera den erhållna dataströmmen till meningsfull data som hjälper till att få insikter som kan användas i datadrivna beslut. Vi kan till exempel behöva generera insikter från rådata som erhållits från IoT-enheter, eller data erhållna från sociala medieplattformar i realtid och utföra en analys eller bearbetning och visa upp dem för företaget för att fatta bättre beslut eller hjälpa dem att förbättra prestanda för deras tjänster.
För dessa typer av användningsfall skulle vi vilja strömma våra inmatningsdata / rådata till en datasjön, där vi kan lagra våra uppgifter och säkerställa datakvalitet utan att hämma prestandan.
En annan situation, vi kanske läser data direkt från Kafka, är när vi behöver extremt låg end-to-end latens, som matning av data till realtidsapplikationer.
Kafka fastställer vissa funktioner för sina användare:
- Publicera och prenumerera på data.
- Lagra data i den ordning de genererades effektivt.
- Realtid / On-the-fly-behandling av data.
Kafka används mest av tiden för:
- Implementera on-the-fly streaming-dataströmledningar som pålitligt får data mellan två enheter i systemet.
- Implementera on-the-fly streaming-applikationer som transformerar eller manipulerar eller bearbetar dataströmmarna.
Använd fall
Nedan följer några omfattande implementerade fall av Kafka-applikation:
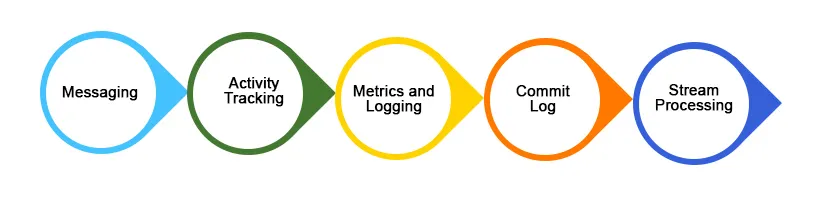
1. Meddelanden
Kafka fungerar bättre än andra traditionella meddelandesystem som ActiveMQ, RabbitMQ osv. Som jämförelse erbjuder Kafka bättre kapacitet, inbyggd partitionsfacilitet, replikering och feltoleransfunktioner, vilket gör det till ett bättre meddelandesystem för storskaliga processapplikationer .
2. Spårning av webbplatsaktiviteter
Användaraktiviteter (sidvyer, sökningar eller alla åtgärder som gjorts) kan spåras och matas för övervakning eller analys i realtid via Kafka eller använda Kafka för att lagra dessa typer av data i Hadoop eller datavarehus för senare bearbetning eller manipulation. Aktivitetsspårning genererar en enorm mängd data som måste överföras till önskad plats utan någon form av dataförlust.
3. Logga aggregering
Loggsamling är en process för att samla / sammanfoga fysiska loggfiler från olika servrar i en applikation till ett enda arkiv (filserver eller HDFS) för bearbetning. Kafka erbjuder bra prestanda, lägre ände-till-än-latens jämfört med Flume.

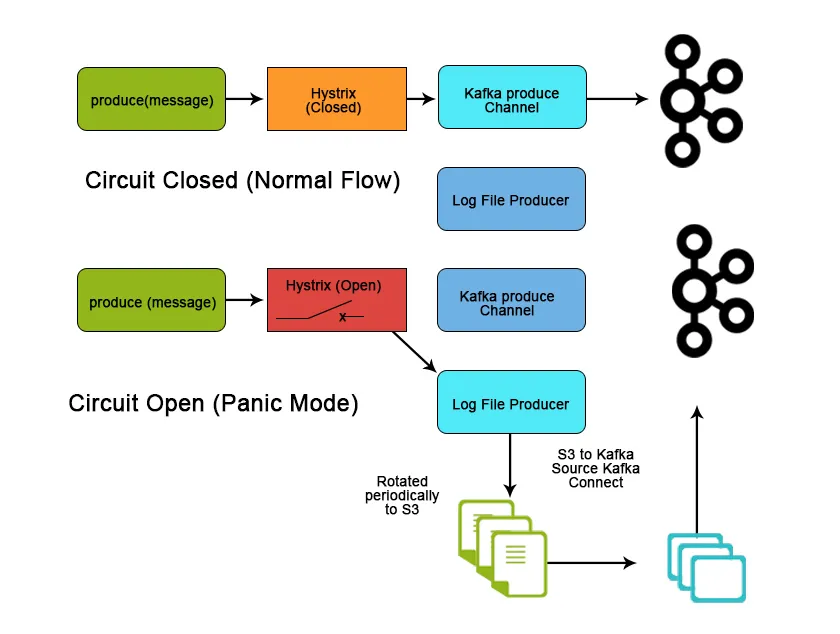
Slutsats
Kafka används kraftigt i stordatautrymmet som ett sätt att ta in och flytta stora mängder data mycket snabbt på grund av dess prestandaegenskaper och funktioner som hjälper till att uppnå skalbarhet, tillförlitlighet och hållbarhet. I den här artikeln diskuterade vi Apache Kafka dess funktioner, användningsfall och tillämpning och vad som gör det till ett bättre verktyg för strömning av data.
Rekommenderade artiklar
Detta är en guide till Kafka Applications. Här diskuterar vi vad som är Kafka tillsammans med toppapplikationer av Kafka som inkluderar omfattande implementerade användningsfall och en del verklig implementering. Du kan också titta på följande artiklar för att lära dig mer-
- Vad är Kafka?
- Hur installerar jag Kafka?
- Kafka intervjufrågor
- Apache Kafka vs Flume
- Topp 8 enheter av IoT som du borde veta
- Kafka vs Kinesis | Skillnader med Infographics
- Olika typer av Kafka-verktyg med komponenter
- Lär dig de bästa skillnaderna mellan ActiveMQ och Kafka