

Skillnaden mellan Hadoop och Hive
Hadoop:
Hadoop är ett ramverk eller programvara som uppfanns för att hantera enorma data eller Big Data. Hadoop används för att lagra och bearbeta stora data som distribueras över ett kluster av varumärkesservrar.
Hadoop lagrar data med hjälp av Hadoop distribuerade filsystem och bearbetar / frågar dem med hjälp av Map Reduce programmeringsmodell.
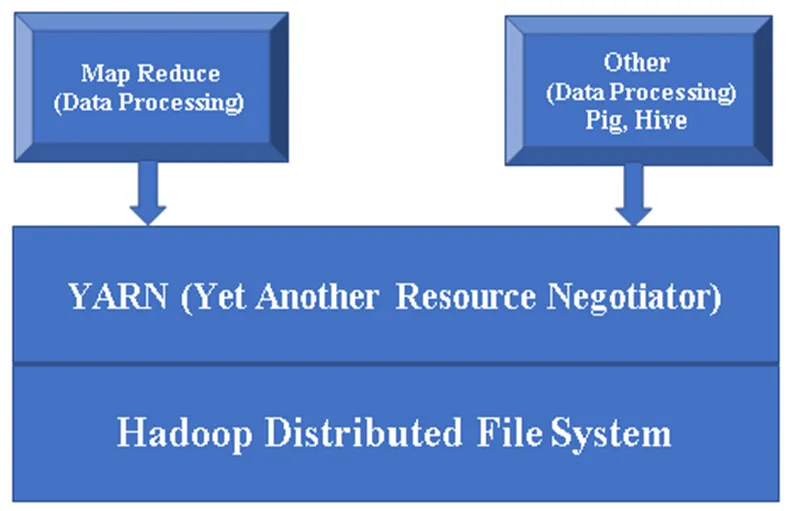
Figur 1, en grundläggande arkitektur för en Hadoop-komponent.
Hadoops huvudkomponenter:
Hadoop Base / Common: Hadoop Common kommer att ge dig en plattform för att installera alla dess komponenter.
HDFS (Hadoop Distribuerat filsystem): HDFS är en viktig del av Hadoop-ramverket och tar hand om all data i Hadoop Cluster. Det fungerar på Master / Slave Architecture och lagrar data med hjälp av replikering.
Master / slavarkitektur och replikering:
- Master Node / Name Node: Name node lagrar metadata för varje block / fil som lagras i HDFS, HDFS kan endast ha en Master Node (i fallet med HA kommer en annan Master Node att fungera som Secondary Master Node).
- Slave Node / Data Node: Datanoder innehåller faktiska datafiler i block. HDFS kan ha flera datanoder.
- Replikation: HDFS lagrar sina data genom att dela upp dem i block. Standardblockstorleken är 64 MB. På grund av att replikationsdata lagras i 3 (standardreplikationsfaktor, kan ökas enligt krav) är olika datanoder följaktligen det minsta möjliga att förlora data i fall av nodfel.
YARN (Yet Another Resource Negotiator): Det används i princip för att hantera Hadoop-resurser också, det spelar en viktig roll i schemaläggningen av användarnas applikation.
MR (Map Reduce): Detta är Hadoops grundläggande programmeringsmodell. Det används för att bearbeta / fråga informationen inom Hadoop-ramverket.
Bikupa:
Hive är en applikation som går över Hadoop-ramverket och ger SQL-liknande gränssnitt för att bearbeta / fråga informationen. Hive är designad och utvecklad av Facebook innan den blir en del av Apache-Hadoop-projektet.
Hive kör sin fråga med HQL (Hive-frågespråk). Hive har samma struktur som RDBMS och nästan samma kommandon kan användas i Hive.
Hive kan lagra data i externa tabeller så det är inte obligatoriskt att använda HDFS, det stöder också filformat som ORC, Avro-filer, sekvensfil och textfiler etc.
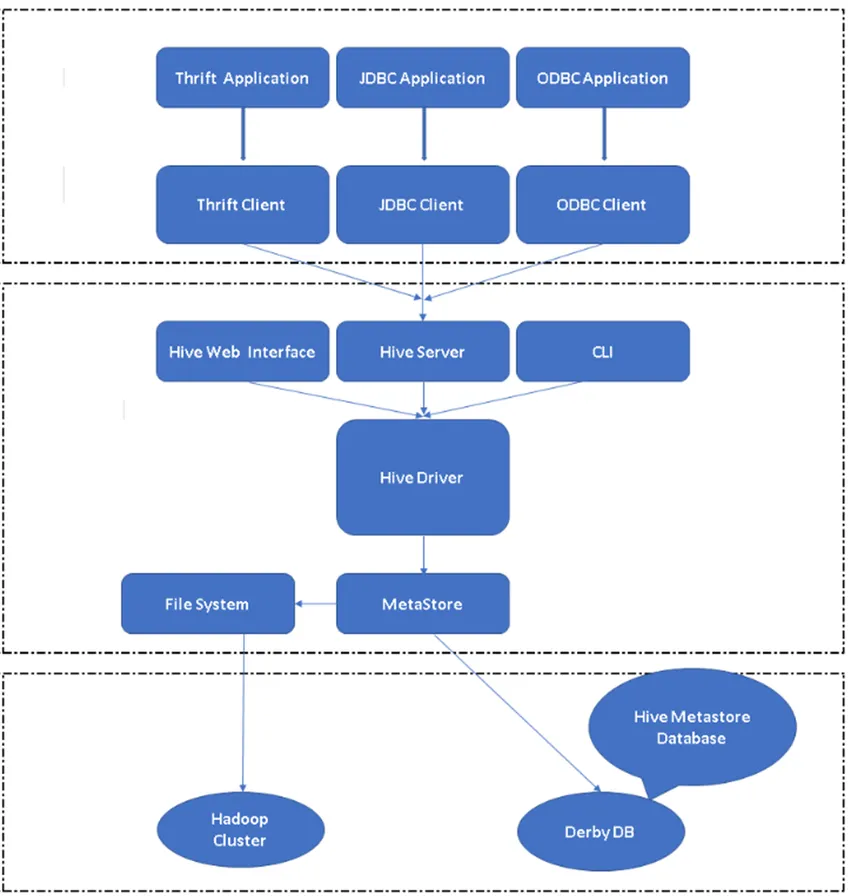
Bild 2, Hive's Architecture & It's huvudkomponenter.
Hives huvudkomponent:
Hive-klienter: Inte bara SQL, Hive stöder också programmeringsspråk som Java, C, Python med olika drivrutiner som ODBC, JDBC och Thrift. Man kan skriva alla hive-klientapplikationer på andra språk och kan köras i Hive med dessa klienter.
Hive-tjänster: Under Hive-tjänster sker exekvering av kommandon och frågor. Hive web interface har fem underkomponenter.
- CLI: Standardgränssnitt för kommandorad som tillhandahålls av Hive för exekvering av Hivefrågor / kommandon.
- Hive-webbgränssnitt: Det är ett enkelt grafiskt användargränssnitt. Det är ett alternativ till Hive-kommandoraden och används för att köra frågor och kommandon i Hive-applikationen.
- Hive Server: Det kallas också Apache Thrift. Det är ansvarigt att ta kommandon från olika-olika kommandoradgränssnitt och skicka alla kommandon / frågor till Hive också det hämtar det slutliga resultatet.
- Apache Hive Driver: Det är ansvarigt för att ta input från CLI, webbgränssnittet, ODBC, JDBC eller Thrift från en klient och skicka informationen till metastore där all filinformation lagras.
- Metastore: Metastore är ett arkiv för att lagra all Hive-metadatainformation. Hives metadata lagrar information som strukturen för tabeller, partitioner och kolumntyp osv …
Hive Storage: Det är den plats där den faktiska uppgiften utförs. Alla frågor som körs från Hive utförde åtgärden inuti Hive-lagring.
Jämförelse mellan Head och Head mellan Hadoop vs Hive (Infographics)
Nedan är skillnaden mellan de 8 bästa mellan Hadoop och Hive
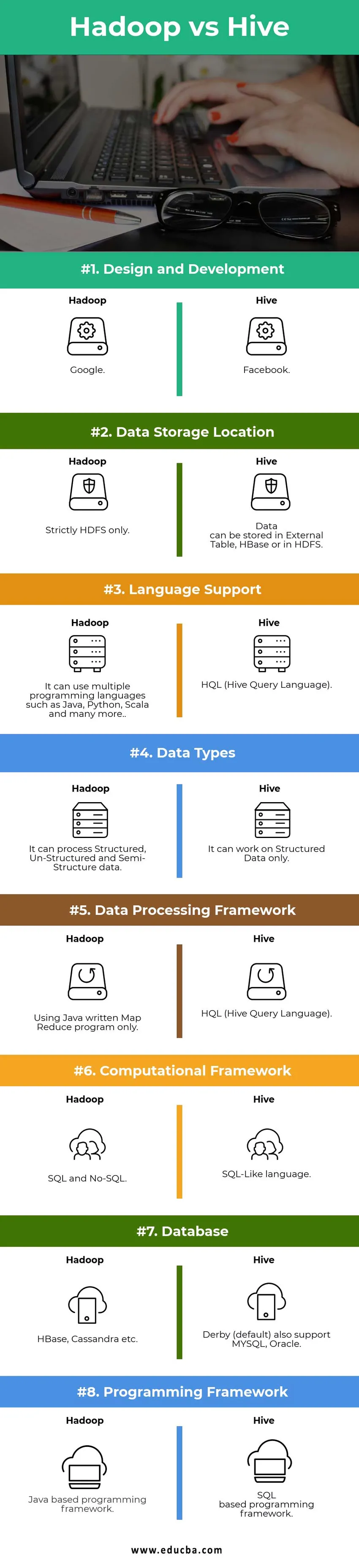
Viktiga skillnader mellan Hadoop vs Hive:
Nedan finns listor över punkter, beskriv om de viktigaste skillnaderna mellan Hadoop och Hive:
1) Hadoop är ett ramverk för att bearbeta / fråga Big Data medan Hive är ett SQL-baserat verktyg som bygger över Hadoop för att bearbeta data.
2) Hiveprocess / fråga alla data med HQL (Hive Query Language) är det SQL-liknande språk medan Hadoop bara kan förstå Map Reduce.
3) Map Reduce är en integrerad del av Hadoop, Hives fråga omvandlas först till Map Reduce än bearbetas av Hadoop för att fråga informationen.
4) Hive fungerar på SQL Like-fråga medan Hadoop förstår det bara med Java-baserad Map Reduce.
5) I Hive kan tidigare använda traditionella "Relational Database's" -kommandon också användas för att fråga stordata medan du är i Hadoop, måste skriva komplexa kartminskningsprogram med Java som inte liknar tradition Java.
6) Hive kan bara bearbeta / fråga de strukturerade data medan Hadoop är avsett för all typ av data oavsett om de är strukturerade, ostrukturerade eller halvstrukturerade.
7) Med hjälp av Hive kan man bearbeta / fråga data utan komplicerad programmering medan man i det enkla Hadoop-ekosystemet behöver skriva ett komplext Java-program för samma data.
8) Hadoop-ramverk på en sida behöver 100-talsrad för att förbereda Java-baserat MR-program, en annan sida Hadoop med Hive kan fråga samma data med 8 till 10 rader HQL.
9) I Hive är det mycket svårt att infoga utgången från en fråga som inmatning från en annan medan samma fråga kan göras enkelt med Hadoop med MR.
10) Det är inte obligatoriskt att ha Metastore inom Hadoop-klusteret medan Hadoop lagrar alla dess metadata inuti HDFS (Hadoop Distribuerat filsystem).
Hadoop vs Hive jämförelsetabell
| Jämförelsepoäng | Bikupa | Hadoop |
|
Design och utveckling | ||
| Datalagringsplats |
Data kan lagras i Extern Tabell, HBase eller i HDFS. | Endast HDFS. |
| Språkstöd | HQL (Hive Query Language) |
Den kan använda flera programmeringsspråk som Java, Python, Scala och många fler. |
| Datatyper | Det kan bara fungera på strukturerade data. |
Det kan behandla strukturerade, ostrukturerade och semistrukturerade data. |
| Ram för databehandling |
HQL (Hive Query Language) | Använd endast Java skriven karta Minska programmet. |
|
Beräkningsram | SQL-liknande språk. | SQL och No-SQL. |
| Databas |
Derby (standard) stöder också MYSQL, Oracle … | HBase, Cassandra osv…. |
| Programmeringsram |
SQL-baserat programmeringsram. | Java-baserad programmeringsram. |
Slutsats - Hadoop vs Hive
Hadoop och Hive används båda för att bearbeta Big data. Hadoop är ett ramverk som tillhandahåller plattform för andra applikationer för att fråga / bearbeta Big Data medan Hive bara är en SQL-baserad applikation som bearbetar data med hjälp av HQL (Hive Query Language)
Hadoop kan användas utan Hive för att bearbeta big data medan det inte är lätt att använda Hive utan Hadoop.
Som en slutsats kan vi inte jämföra Hadoop och Hive på något sätt och i någon aspekt. Både Hadoop och Hive är helt olika. Att använda båda teknologierna tillsammans kan göra Big Data-frågeprocessen mycket enklare och bekväm för Big Data-användare.
Rekommenderade artiklar:
Detta har varit en guide till Hadoop vs Hive, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Hadoop vs Apache Spark - Intressanta saker du behöver veta
- HADOOP vs RDBMS | Vet de 12 användbara skillnaderna
- Hur stor data förändrar hälsoomsorgens ansikte
- Topp 12 jämförelse av Apache Hive vs Apache HBase (Infographics)
- Fantastisk guide för Hadoop vs Spark