
Skillnaden mellan maskininlärning och prediktiv analys
Maskininlärning är ett område inom datavetenskap, som växer steg och binds i dag. De senaste framstegen inom hårdvaruteknologier som resulterade i en enorm ökning av beräkningskraften som GPU (grafiska bearbetningsenheter) och framsteg i neurala nätverk, maskininlärning har blivit ett surrord. I huvudsak kan vi använda maskininlärningstekniker bygga algoritmer för att extrahera data och se viktig dold information från den. Predictive analytics är också en del av maskininlärningsdomänen som är begränsad för att förutsäga det framtida resultatet från data baserat på tidigare mönster. Medan prediktiv analys har använts sedan mer än två decennier främst inom bank- och finanssektorn, har tillämpning av maskininlärning tagit framträdande på senare tid med algoritmer som objektdetektering från bilder, textklassificering och rekommendationssystem.
Maskininlärning
Maskininlärning internt använder statistik, matematik och datavetenskapliga grundläggande för att bygga logik för algoritmer som kan göra klassificering, förutsägelse och optimering i såväl realtider som batchläge. Klassificering och regression är två huvudklasser av ett problem under maskininlärning. Låt oss förstå både maskininlärning och prediktiv analys i detalj.
Klassificering
Under dessa hinkar av ett problem tenderar vi att klassificera ett objekt baserat på dess olika egenskaper i en eller flera klasser. Till exempel att klassificera en bankkund för att vara berättigad till ett hemlån eller inte baserat på hans / hennes kredithistoria. Vanligtvis skulle vi ha transaktionsdata tillgängliga för kunden som hans ålder, inkomst, utbildningsbakgrund, hans arbetslivserfarenhet, bransch där han arbetar, antal beroende, månatliga utgifter, eventuella tidigare lån, hans utgiftsmönster, kredithistoria, etc. och baserat på denna information tenderar vi att beräkna om han skulle få lån eller inte.
Det finns många vanliga maskininlärningsalgoritmer som används för att lösa klassificeringsproblemet. Logistisk regression är en sådan metod, förmodligen den mest använda och mest välkända, också den äldsta. Utöver detta har vi också några av de mest avancerade och komplicerade modellerna, från beslutsträd till slumpmässig skog, AdaBoost, XP boost, supportvektomaskiner, naiv baize och neuralt nätverk. Sedan de senaste åren körs djup inlärning i framkant. Vanligtvis används neuralt nätverk och djup inlärning för att klassificera bilder. Om det finns hundra tusen bilder av katter och hundar och du vill skriva en kod som automatiskt kan separera bilder av katter och hundar, kanske du vill gå till djupa inlärningsmetoder som ett convolutional neuralt nätverk. Fackla, café, sensorflöde, etc. är några av de populära biblioteken i python för att göra djup inlärning.
För att mäta noggrannheten hos regressionsmodeller används mätningar som falsk positiv hastighet, falsk-negativ hastighet, känslighet etc.
regression
Regression är en annan klass av problem i maskininlärning där vi försöker förutsäga det kontinuerliga värdet för en variabel i stället för en klass till skillnad från klassificeringsproblem. Regressionstekniker används vanligtvis för att förutsäga aktiekursen på ett lager, försäljningspriset för ett hus eller en bil, en efterfrågan på en viss artikel, etc. När tidsserieegenskaper också spelar in blir regressionsproblem mycket intressanta att lösa. Linjär regression med vanliga minsta kvadrat är en av de klassiska maskininlärningsalgoritmerna inom detta domän. För tidsseriebaserat mönster används ARIMA, exponentiellt rörligt medelvärde, viktat rörligt medelvärde och enkelt rörligt medelvärde.
För att mäta noggrannheten hos regressionsmodeller används mätningar som medelvärdesfel, absolut medelkvadratfel, rotmåttfel osv.
Predictive Analytics
Det finns vissa områden med överlappning mellan maskininlärning och prediktiv analys. Även om vanliga tekniker som logistik och linjär regression omfattas av både maskininlärning och prediktiv analys, är avancerade algoritmer som ett beslutsträd, slumpmässig skog etc. i huvudsak maskininlärning. Under prediktiv analys förblir målet med problemen mycket smalt där avsikten är att beräkna värdet på en viss variabel vid en framtida tidpunkt. Predictive analytics är mycket statistik laddad medan maskininlärning är mer en blandning av statistik, programmering och matematik. En typisk prediktiv analytiker lägger sin tid på att beräkna t kvadrat, f-statistik, Innova, chi-kvadrat eller vanlig minst kvadrat. Frågor som om uppgifterna normalt distribueras eller skev, om studentens t-distribution ska användas eller klockkurva används, ska alfa tas med 5% eller 10% bugg dem hela tiden. De letar efter djävulen i detaljer. En maskinutbildningsingenjör bryr sig inte om många av dessa problem. Deras huvudvärk är helt annorlunda, de befinner sig fastade på noggrannhetsförbättring, falsk-positiv hastighetsminimering, överliggande hantering, normalisering av intervall eller validering av k gånger.
En prediktiv analytiker använder mestadels verktyg som Excel. Scenario eller målsökning är deras favorit. De använder ibland VBA eller mikron och skriver knappast någon lång kod. En maskininlärande ingenjör lägger hela sin tid på att skriva komplicerad kod utöver vanlig förståelse, han använder verktyg som R, Python, Saas. Programmering är deras huvudsakliga arbete, fixa buggar och testa de olika landskapen en daglig rutin.
Dessa skillnader ger också en stor skillnad i deras efterfrågan och lön. Medan prediktiva analytiker är så igår är maskininlärning framtiden. En typisk maskinutbildningsingenjör eller datavetare (som oftast kallas idag) betalas 60-80% mer än en typisk mjukvaruingenjör eller förutsägbar analytiker för den delen och de är nyckeldrivrutinen i dagens teknikaktiverade värld. Uber, Amazon och nu självkörande bilar är också möjliga endast på grund av dem.
Jämförelse mellan head-to-head-jämförelse mellan maskininlärning och förutsägbar analys (infographics)
Nedan visas de 7 bästa jämförelserna mellan maskininlärning och prediktiv analys
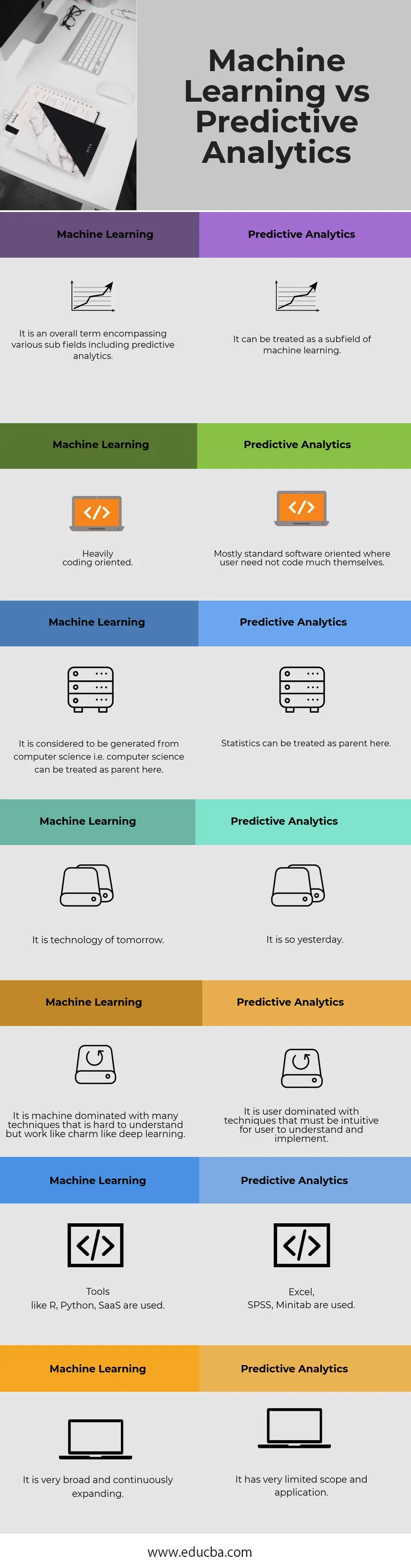
Machine Learning vs Predictive Analytics jämförelsetabell
Nedan är den detaljerade förklaringen av Machine Learning vs Predictive Analytics
| Maskininlärning | Predictive Analytics |
| Det är en övergripande term som omfattar olika underfält inklusive prediktiv analys. | Det kan behandlas som ett underfält för maskininlärning. |
| Kraftigt kodningsorienterat. | Vanligtvis standard mjukvaruorienterad där en användare inte behöver koda mycket själva |
| Det anses vara genererat från datavetenskap, dvs. datavetenskap kan behandlas som förälder här. | Statistik kan behandlas som förälder här. |
| Det är morgondagens teknik. | Det är så igår. |
| Det är en maskin som domineras av många tekniker som är svåra att förstå men fungerar som charm som djup inlärning. | Det är användardominerat med tekniker som måste vara intuitivt för en användare att förstå och implementera. |
| Verktyg som R, Python, SaaS används. | Excel, SPSS, Minitab används. |
| Det är mycket brett och expanderar kontinuerligt. | Det har ett mycket begränsat omfattning och tillämpning. |
Slutsats - Machine Learning vs Predictive Analytics
Från ovanstående diskussion om både Machine Learning och Predictive Analytics är det uppenbart att prediktiv analys i princip är ett underområde för maskininlärning. Maskininlärning är mer mångsidig och kan lösa ett brett spektrum av problem.
Rekommenderad artikel
Detta har varit en guide till Machine Learning vs Predictive Analytics, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Lär dig Big Data Vs Machine Learning
- Skillnaden mellan datavetenskap och maskininlärning
- Jämförelse mellan Predictive Analytics vs Data Science
- Data Analytics mot Predictive Analytics - Vilken är användbar