
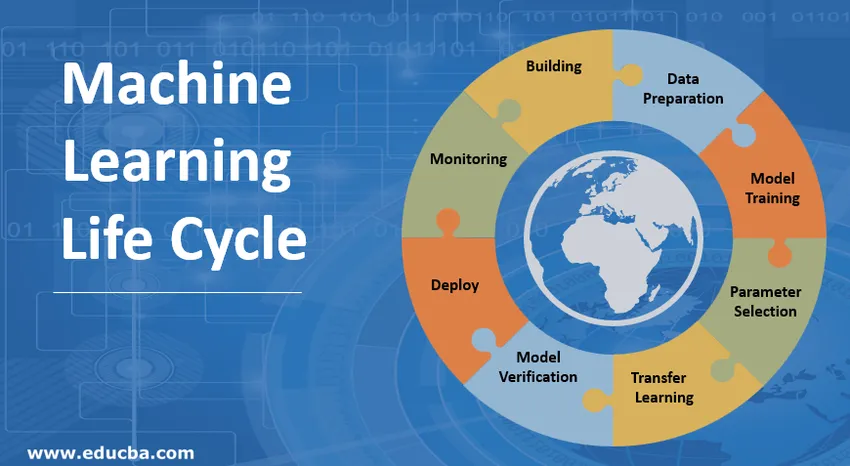
Introduktion till maskinlärande livscykel (ML)
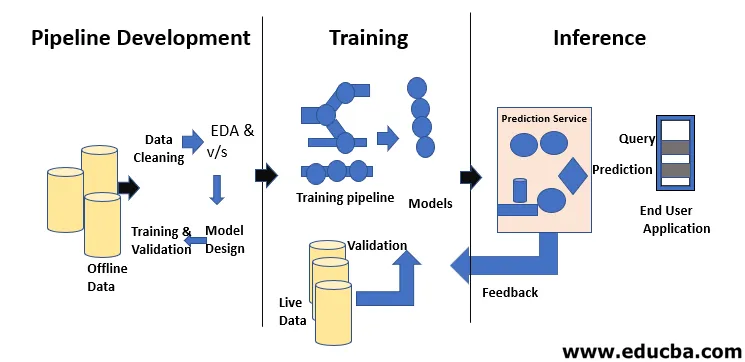
Machine Learning Life Cycle handlar om att skaffa kunskap genom data. Livscykeln för maskininlärning beskriver en trefasprocess som används av datavetare och datatekniker för att utveckla, utbilda och betjäna modeller. Utveckling, utbildning och service av maskininlärningsmodeller är resultatet av en process som kallas maskininlärningens livscykel. Det är ett system som använder data som input, med förmågan att lära sig och förbättra med hjälp av algoritmer utan att programmeras för det. Maskinens inlärningscykel har tre faser som visas i figuren nedan: pipeline-utveckling, träning och inferens.
Det första steget i maskinlärande livscykel består av att omvandla rådata till ett rengjort datasystem, det datasättet delas ofta och återanvändas. Om en analytiker eller en datavetare som stöter på problem i den mottagna informationen måste de få åtkomst till originaldata och transformationsskript. Det finns olika orsaker till att vi kanske vill återgå till tidigare versioner av våra modeller och data. Att hitta den tidigare bästa versionen kan till exempel kräva att du söker igenom många alternativa versioner eftersom modeller oundvikligen försämras i sin prediktiva kraft. Det finns många orsaker till denna försämring, som en förskjutning i distributionen av data som kan resultera i en snabb nedgång i förutsägelseskraften som kompensation för fel. Att diagnostisera denna nedgång kan kräva jämförelse av träningsdata med livedata, omskolning av modellen, omprövning av tidigare designbeslut eller till och med omdesign av modellen.
Lärande av misstag
Utvecklingen av modeller kräver separat utbildnings- och testdatasystem. Överanvändning av testdata under träning kan leda till dålig generalisering och prestanda, eftersom de kan leda till överanpassning. Kontext spelar en viktig roll här, därför är det nödvändigt att förstå vilka data som användes för att träna de avsedda modellerna och med vilka konfigurationer. Maskinens inlärningscykel är datadriven eftersom modellen och utdata från utbildningen är kopplad till de uppgifter som den utbildades på. En översikt över en inlärningsrörledning för maskin till slut med en dataperspektiv visas i figuren nedan:
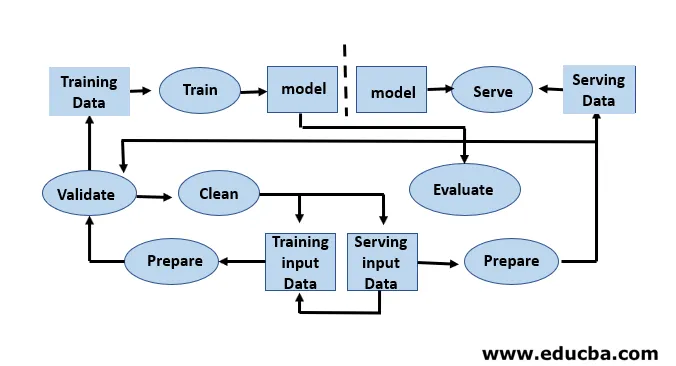
Steg involverade i maskinlärande livscykel
Machine Learning-utvecklare utför ständigt experiment med nya datasätt, modeller, programvarubibliotek, inställning av parametrar för att optimera och förbättra modellens noggrannhet. Eftersom modellprestanda beror helt på inmatningsdata och träningsprocessen.
1. Bygga upp maskininlärningsmodellen
Detta steg bestämmer vilken typ av modell som baseras på applikationen. Den finner också att tillämpningen av modellen i modellinlärningsstadiet så att de kan utformas korrekt efter behovet av en avsedd applikation. En mängd olika modeller för maskininlärning finns tillgängliga, till exempel övervakad modell, oövervakad modell, klassificeringsmodeller, regressionsmodeller, klustermodeller och förstärkningsmodeller. En nära inblick visas i figuren nedan:
2. Förberedelse av data
En mängd data kan användas som input för maskininlärningsändamål. Dessa uppgifter kan komma från ett antal källor, till exempel ett företag, läkemedelsföretag, IoT-enheter, företag, banker, sjukhus osv. Stora mängder data tillhandahålls i maskinens inlärningsstadium eftersom antalet data ökar anpassar det sig mot vilket ger önskade resultat. Denna utgångsdata kan användas för analys eller matas som inmatning i andra maskininlärningsapplikationer eller system för vilka de kommer att fungera som ett frö.
3. Model Training
Det här steget handlar om att skapa en modell utifrån de uppgifter som ges till den. I detta skede används en del av träningsdata för att hitta modellparametrar såsom koefficienterna för ett polynom eller vikter i maskininlärning vilket hjälper till att minimera felet för den givna datamängden. Resterande data används sedan för att testa modellen. Dessa två steg upprepas vanligtvis ett antal gånger för att förbättra modellens prestanda.
4. Val av parameter
Det innebär valet av parametrar som är associerade med träningen som också kallas hyperparametrar. Dessa parametrar styr effektiviteten i träningsprocessen och därmed beror slutligen modellens prestanda på detta. De är mycket viktiga för en framgångsrik produktion av maskininlärningsmodellen.
5. Överför lärande
Eftersom det finns många fördelar med att återanvända maskininlärningsmodeller över olika domäner. Trots det faktum att en modell inte kan överföras mellan olika domäner direkt används den därför för att tillhandahålla ett utgångsmaterial för att påbörja utbildningen av en nästa stegmodell. Således minskar den träningstiden avsevärt.
6. Verifiering av modeller
Ingången till detta steg är den utbildade modellen som produceras av modellinlärningssteget och utgången är en verifierad modell som ger tillräcklig information för att användare ska kunna avgöra om modellen är lämplig för dess avsedda tillämpning. Detta steg i maskinlärningens livscykel handlar alltså om att en modell fungerar korrekt när den behandlas med osynliga ingångar.
7. Distribuera maskininlärningsmodellen
I detta skede av maskinlärande livscykel använder vi oss för att integrera maskininlärningsmodeller i processer och applikationer. Det ultimata syftet med detta steg är modellens korrekta funktionalitet efter installationen. Modellerna bör distribueras på ett sådant sätt att de kan användas för slutsatser såväl som att de bör uppdateras regelbundet.
8. Övervakning
Det inbegriper införandet av säkerhetsåtgärder för att säkerställa att modellen fungerar korrekt under dess livslängd. För att detta ska ske krävs ordentlig hantering och uppdatering.
Fördel med maskinlärande livscykel
Maskininlärning ger fördelarna med kraft, hastighet, effektivitet och intelligens genom inlärning utan att uttryckligen programmera dessa till en applikation. Det ger möjligheter till förbättrad prestanda, produktivitet och robusthet.
Slutsats - livscykel för maskininlärning
Maskininlärningssystem blir viktigare dag för dag eftersom mängden data involverad i olika applikationer ökar snabbt. Maskininlärningsteknologi är hjärtat i smarta enheter, hushållsapparater och onlinetjänster. Framgången för maskininlärning kan ytterligare utvidgas till säkerhetskritiska system, datahantering, högpresterande datoranläggning, som har stor potential för applikationsdomäner.
Rekommenderade artiklar
Detta är en guide till maskininlärning livscykel. Här diskuterar vi introduktionen, Learning From Mistakes, Steps Involved in Machine Learning Livscykel och fördelar. Du kan också gå igenom våra andra artiklar som föreslås för att lära dig mer–
- Artificiell intelligensföretag
- QlikView Set-analys
- IoT ekosystem
- Cassandra Data Modeling