

Introduktion till linjär regressionsanalys
Det är ofta förvirrande att lära sig ett koncept som till och med är en del av vårt dagliga liv. Men det är inte ett problem, vi kan hjälpa och utveckla oss själva för att lära av våra vardagliga aktiviteter bara genom att analysera saker och inte känna oss rädda för att ställa frågor. Varför priset påverkar efterfrågan på varorna, varför ränteförändring påverkar pengemängden. Alla dessa kan besvaras med en enkel metod som kallas linjär regression. Den enda komplexiteten som man känner när man arbetar med linjär regressionsanalys är identifieringen av beroende och oberoende variabler.
Vi måste hitta vad som påverkar vad och hälften av problemet är löst. Vi måste se om det är pris eller efterfrågan som påverkar varandras beteende. När vi fick veta vilken som är den oberoende variabeln och den beroende variabeln är vi bra att gå till vår analys. Det finns flera typer av regressionsanalyser tillgängliga. Denna analys beror på de variabler som finns tillgängliga för oss.
De tre typerna av regressionsanalys
Dessa tre regressionsanalyser har maximalt användningsfall i den verkliga världen, annars finns det mer än 15 typer av regressionsanalyser. Typer av regressionsanalys som vi ska diskutera är:
- Linjär regressionsanalys
- Multipel linjär regressionsanalys
- Logistisk återgång
I den här artikeln kommer vi att fokusera på Simple Linear Regression-analys. Denna analys hjälper oss att identifiera förhållandet mellan den oberoende faktorn och den beroende faktorn. Med enklare ord hjälper Regression-modellen oss att hitta hur förändringarna i den oberoende faktorn påverkar den beroende faktorn. Denna modell hjälper oss på flera sätt som:
- Det är en enkel och kraftfull statistisk modell
- Det kommer att hjälpa oss att göra förutsägelser och prognoser
- Det hjälper oss att fatta ett bättre affärsbeslut
- Det hjälper oss att analysera resultaten och korrigera fel
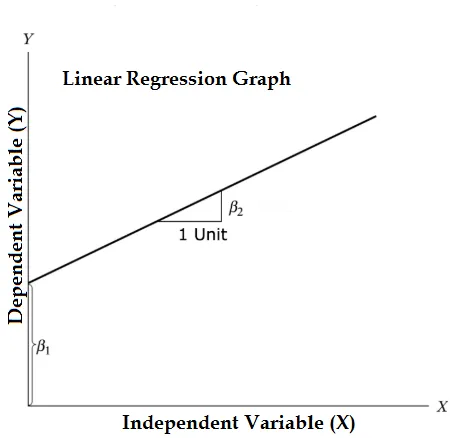
Ekvationen för linjär regression och dela upp den i relevanta delar
Y = ß1 + ß2X + ϵ
- Där β1 i den matematiska terminologin känd som avlyssning och β2 i den matematiska terminologin känd som en sluttning. De är också kända som regressionskoefficienter. ϵ är feltermen, det är den del av Y som regressionsmodellen inte kan förklara.
- Y är en beroende variabel (andra termer som utbytbart används för beroende variabler är svarsvariabel, regressand, uppmätt variabel, observerad variabel, svarsvariabel, förklarad variabel, utfallsvariabel, experimentell variabel och / eller utgångsvariabel).
- X är en oberoende variabel (regressorer, kontrollerad variabel, manipulerad en variabel, förklarande variabel, exponeringsvariabel och / eller ingångsvariabel).
Problem: För att förstå vad som är linjär regressionsanalys tar vi datan "Cars" som kommer som standard i R-kataloger. I detta dataset finns det 50 observationer (i princip rader) och 2 variabler (kolumner). Kolumnnamnen är “Dist” och “Speed”. Här måste vi se påverkan på avståndsvariabler på grund av ändringshastighetsvariabler. För att se strukturen för data kan vi köra en kod Str (dataset). Den här koden hjälper oss att förstå strukturen för datasatsen. Dessa funktioner hjälper oss att fatta bättre beslut eftersom vi har en bättre bild i vårt sinne om datastrukturen. Den här koden hjälper oss att identifiera typen av datasätt.
Koda:

På liknande sätt för att kontrollera statistikkontrollpunkterna för datasättet kan vi använda kodöversikt (bilar). Den här koden tillhandahåller ett medelvärde, median, intervall för datasättet på en gång, som forskaren kan använda när han hanterar problemet.
Produktion:
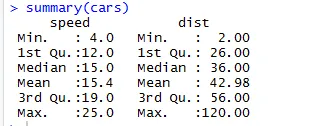
Här kan vi se den statistiska utgången för varje variabel vi har i vårt datasæt.
Den grafiska representationen av databas
Typer av grafisk representation som kommer att täcka här är och varför:
- Scatterplott: Med hjälp av diagrammet kan vi se i vilken riktning vår linjära regressionsmodell går, om det finns några starka bevis för att bevisa vår modell eller inte.
- Box Plot: Hjälper oss att hitta utdelare.
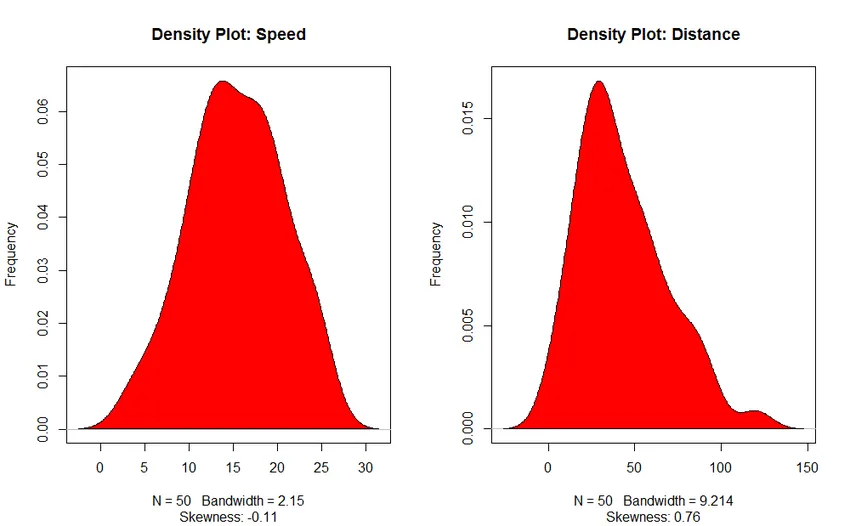
- Density Plot: Hjälp oss att förstå fördelningen av den oberoende variabeln, i vårt fall är den oberoende variabeln "Speed".
Fördelar med grafisk representation
Här är följande fördelar:
- Lätt att förstå
- Hjälper oss att fatta ett snabbt beslut
- Jämförande analys
- Mindre ansträngning och tid
1. Scatterplott: Det hjälper till att visualisera alla relationer mellan den oberoende variabeln och den beroende variabeln.
Koda:

Produktion:
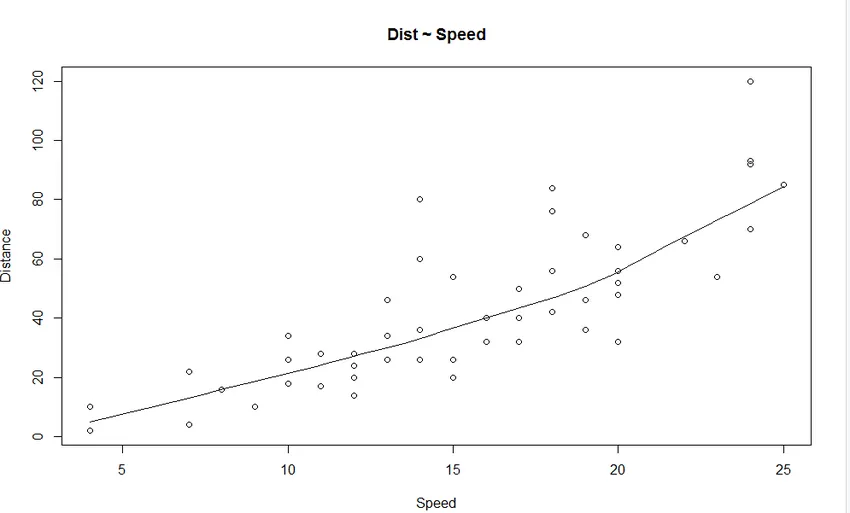
Vi ser från diagrammet ett linjärt ökande förhållande mellan den beroende variabeln (Distans) och den oberoende variabeln (Speed).
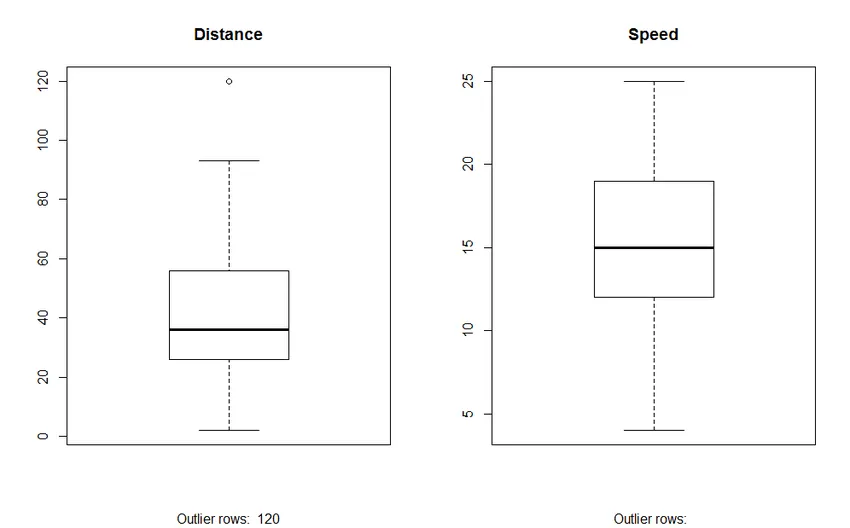
2. Box Plot: Box plot hjälper oss att identifiera outliers i datasätten. Fördelarna med att använda en ruta är:
- Grafisk visning av variablernas placering och spridning.
- Det hjälper oss att förstå datans skevhet och symmetri.
Koda:

Produktion:
3. Densitetsplott (för att kontrollera distributionens normalitet)
Koda:
 Produktion:
Produktion:
Korrelationsanalys
Denna analys hjälper oss att hitta förhållandet mellan variablerna. Det finns huvudsakligen sex typer av korrelationsanalys.
- Positiv korrelation (0, 01 till 0, 99)
- Negativ korrelation (-0, 99 till -0, 01)
- Ingen korrelation
- Perfekt korrelation
- Stark korrelation (ett värde närmare ± 0, 99)
- Svag korrelation (ett värde närmare 0)
Scatter-plot hjälper oss att identifiera vilka typer av korrelationsdatasätt som finns bland dem och koden för att hitta korrelationen är

Produktion:
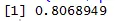
Här har vi en stark positiv korrelation mellan hastighet och avstånd, vilket innebär att de har en direkt relation mellan dem.
Linjär regressionsmodell
Detta är kärnkomponenten i analysen, tidigare försökte vi bara testa saker om datasättet vi har är logiskt nog för att köra en sådan analys eller inte. Funktionen vi planerar att använda är lm (). Denna funktion innehåller två element som är formel och data. Innan vi tilldelar vilken variabel som är beroende eller oberoende måste vi vara mycket säkra på det eftersom hela vår formel beror på det.
Formeln ser ut så här,
Linjär regression <- lm (beroende variabel ~ oberoende variabel, data = datum. Ram)
Koda:

Produktion:
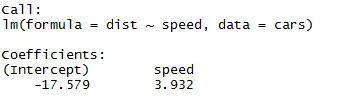
Som vi kan komma ihåg från artikeln ovan i artikeln är ekvationen för linjär regression:
Y = ß1 + ß2X + ϵ
Nu passar vi in den information som vi fick från koden ovan i denna ekvation.
dist = −17.579 + 3.932 ∗ hastighet
Endast att hitta ekvationen för linjär regression är inte tillräcklig, vi måste också kontrollera dess statistik som är signifikant. För detta måste vi skicka en kod "Sammanfattning" på vår linjära regressionsmodell.
Koda:

Produktion:

Det finns flera sätt att kontrollera statistikens betydelse för en modell, här använder vi P-värde-metoden. Vi kan betrakta en modell som är statistiskt anpassad när P-värdet är mindre än den förutbestämda statistiska signifikanta nivån, vilket helst är 0, 05. Vi kan se i vår sammanfattningstabell (linjär_regression) att P-värdet ligger under 0, 05-nivå, så vi kan dra slutsatsen att vår modell är statistiskt signifikant. När vi är säkra på vår modell kan vi använda vårt datasæt för att förutsäga saker.
Rekommenderade artiklar
Detta är en guide till linjär regressionsanalys. Här diskuterar vi de tre typerna av linjär regressionsanalys, den grafiska representationen av databas med fördelar och linjära regressionsmodeller. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer-
- Regressionsformel
- Regressionstestning
- Linjär regression i R
- Typer av dataanalysstekniker
- Vad är regressionsanalys?
- Top Differences of Regression vs Classification
- Topp 6 skillnader av linjär regression vs logistisk regression