

Skillnaden mellan MapReduce och Spark
Map Reduce är en öppen källkodsram för att skriva data till HDFS och bearbeta strukturerade och ostrukturerade data som finns i HDFS. Map Reduce är begränsat till batchbearbetning och på andra kan Spark utföra alla typer av bearbetning. SPARK är en oberoende bearbetningsmotor för realtidsbehandling som kan installeras på alla distribuerade filsystem som Hadoop. SPARK ger en prestanda som är 10 gånger snabbare än Map Reduce på disken och 100 gånger snabbare än Map Reduce på ett nätverk i minnet.
Behov av SPARK
- Iterativ analys: Kartminskning är inte lika effektiv som SPARK för att lösa problem som kräver iterativ analys som det måste gå till disk för varje iteration.
- Interaktiv analys: Kartminskning används ofta för att köra ad-hocfrågor för vilka det behöver komma till på minnet, vilket igen inte är lika effektivt som SPARK eftersom det senare hänvisar till i minnet som är snabbare.
- Inte lämpligt för OLTP: Eftersom det fungerar i det batchorienterade ramverket är det inte lämpligt för ett stort antal av den korta transaktionen.
- Inte lämplig för graf: Apache Graph-biblioteket bearbetar diagrammet som lägger mer komplexitet till Map Reduce.
- Inte lämpligt för triviala operationer: För operationer som ett filter och sammanfogningar kan vi behöva skriva om jobben, som blir mer komplex på grund av nyckelvärdesmönstret.
Jämförelse mellan head-to-head-jämförelse mellan MapReduce vs Spark (Infographics)
Nedan visas de 15 bästa skillnaderna mellan MapReduce och Spark

Viktiga skillnader mellan MapReduce vs Spark
Nedan finns listor med punkter, beskriv de viktigaste skillnaderna mellan MapReduce och Spark:
- Spark är lämplig för realtid eftersom den bearbetar med minnet medan MapReduce är begränsad till batchbehandling.
- Spark har RDD (Resilient Distribuerad Dataset) som ger oss operatörer på hög nivå, men i Map reducerar måste vi koda varje operation som gör det relativt svårt.
- Spark kan bearbeta grafer och stöder maskininlärningsverktyget.
- Nedan är skillnaden mellan MapReduce vs Spark ekosystem.
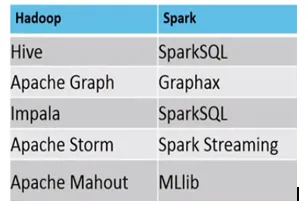
Exempel, där MapReduce vs Spark är lämpliga är följande
Spark: Upptäckt av kreditkortsbedrägeri
MapReduce: Göra regelbundna rapporter som kräver beslutsfattande.
MapReduce vs Spark Comparision Table
| Grund för jämförelse | MapReduce | Gnista |
| Ramverk | En öppen källkodsram för att skriva data till HDFS och bearbeta strukturerade och ostrukturerade data som finns i HDFS. | En öppen källkodsram för snabbare och generell databehandling |
| Hastighet | Map-Reduce bearbeta data (läs och skriv) från disken så att sippan går långsamt jämfört med Spark. | Spark är minst 10 gånger snabbare på disken och 100X snabbare i minnet som Map Reduce. |
| Svårighet | Vi måste koda / hantera varje process. | Med tillgängligheten av RDD (Resilient Distribuerad Dataset) är det enkelt att programmera. |
| Realtid | Inte lämplig för OLTP-transaktion endast för Batch-läge | Den kan hantera realtidsbehandling. Använda SPARK Streaming. |
| Latens | Hög nivå latens beräkning ram | Beräkningsram för låg nivå för latens. |
| Feltolerans | Mästerdemoner kontrollerar slavdemons hjärtslag och om slavdemoner misslyckas planerar mästerdemoner alla pågående och pågående operationer till en annan slav. | RDD: er ger feltolerans för SPARK. De hänvisar till den datamängd som finns i extern lagring som (HDFS, HBase) och fungerar parallellt. |
| Schemaläggare | I Map Reduce använder vi en extern schemaläggare som Oozie. | Eftersom SPARK arbetar med datorminne, fungerar det som sin egen schemaläggare. |
| Kosta | Map Reduce är jämförelsevis billigare jämfört med SPARK. | Som det fungerar i minnet så det kräver mycket RAM vilket gör det relativt dyrare. |
| Plattform utvecklad på | Map Reduce har utvecklats med Java. | SPARK har utvecklats med Scala. |
| Språk som stöds | Karta Minska stöder i princip C, C ++, Ruby, Groovy, Perl, Python. | Spark stöder Scala, Java, Python, R, SQL. |
| SQL-support | Map Reduce kör frågor med Hive Query Language. | Spark har sitt eget frågespråk som kallas Spark SQL. |
| skalbarhet | I Map Reduce kan vi lägga till upp till n antal noder. Den största Hadoop Cluster har 14000 noder. | I Spark kan vi också lägga till ett antal noder. Det största Spark-klustret har 8000 noder. |
| Maskininlärning | Map Reduce stöder Apache Mahout-verktyg för maskininlärning. | Spark stöder MLlib-verktyg för maskininlärning. |
| caching | Kartminskning kan inte cache i minnedata så det är inte så snabbt jämfört med Spark. | Spark cachar data i minnet för ytterligare iterationer så det är mycket snabbt jämfört med Map Reduce. |
| säkerhet | Map Reduce stöder fler säkerhetsprojekt och funktioner jämfört med Spark | Gnissäkerhet är ännu inte mognad som den för Map Reduce |
Slutsats - MapReduce vs Spark
Enligt ovanstående skillnad mellan MapReduce och Spark är det ganska tydligt att SPARK är en mycket mer avancerad datormotor jämfört med Map Reduce. Spark är kompatibelt med alla typer av filformat och också ganska snabbare än Map Reduce. Gnisten har dessutom grafbehandling och maskininlärning.
Å ena sidan är Map Reduce begränsad till batchbearbetning och å andra sidan kan Spark utföra alla typer av behandlingar (batch, interaktiv, iterativ, streaming, graf). På grund av stor kompatibilitet är Spark favorit hos Data Scientist och därmed ersätter Map Reduce och växer snabbt. Men ändå måste vi lagra uppgifterna i HDFS och vi kan också ibland behöva HBase. Så vi måste köra både Spark och Hadoop för att bli bäst.
Rekommenderade artiklar:
Detta har varit en guide till MapReduce vs Spark, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- 7 viktiga saker om Apache Spark (guide)
- Hadoop vs Apache Spark - Intressanta saker du behöver veta
- Apache Hadoop vs Apache Spark | Topp 10 jämförelser du måste känna till!
- Hur MapReduce fungerar?
- Confluence of Technology & Business analytics