

Skillnaden mellan Data mining och Web mining
Data mining : Det är ett begrepp att identifiera ett betydande mönster från data som ger ett bättre resultat. Identifiera mönster varifrån? Från de data som genereras från systemen.
Webbbrytning : Processen för att utföra Data mining på webben kallas Web mining. Extrahera webbdokumenten och upptäck mönstren från det.
Exempel: Tekniker som används för prediktiv analys. (Väderprognos baserad på att identifiera mönstren från historiedata)
Låter oss förstå den stora skillnaden mellan data mining och web mining i detalj i det här inlägget.
Analogi
Guld produceras genom processen som kallas guldbrytning. Det extraheras och förädlas från malmen. Det slutliga resultatet av guldbrytning är ädelmetallen. Likaså,
För att få nyckelinformation (data som är värt) från en rå källa tillämpas dataminingsteknik. Här anses det mönster som upptäckts från den råa datakällan vara värdefull för dataanalytiker / datavetare för att kunna fortsätta med beslutsfattandet som påverkar affärsvärdet.
Data mining
Enkelt uttryckt är data mining ett begrepp om gruvkunskap från olika uppsättningar av data. Den utvunna kunskapen används vidare för att ge prognoser eller rekommendationer. Data som ska brytas finns antingen tillgängliga i datalageret eller i andra externa system. Data kan finnas tillgängliga i olika tabeller med dess olika beteende eller attribut. För att identifiera mönstret måste sambandet mellan flera uppsättningar av data identifieras.
Steg i data mining
Eftersom dataanläggning är ett abstrakt, här är listan över involverade steg,
- Förberedelse av data
- Mönsterupptäckt
- Bygg modeller för att förutse / rekommendera (för att nämna några fall)
- Sammanfatta modellvärdet
Webbbrytning
Webbbrytning är ett abstrakt eftersom det finns tre olika typer av gruvtekniker.
- Webbinnehåll gruvdrift
- Webbstruktur gruvdrift
- Gruv för webbanvändning
Webbgruvsklasser av informationsinsamling 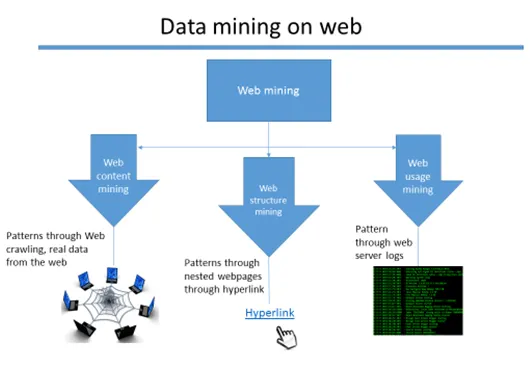
Webbinnehåll gruvdrift
Data från webbsidorna extraheras för att upptäcka olika mönster som ger en viktig insikt. Det finns många tekniker för att extrahera data som webbskrapning (till exempel - skrapor och Octoparse är de välkända verktygen som utför gruvprocessen för webbinnehåll.
Ett av de bästa exemplen - För att genomföra ett evenemang eller något program, analyserar organisationen först om platserna (vilken plats som är bäst lämpad för att genomföra programmet så att det blir fullt deltagande). För att kunna utföra dessa analyser måste man samla in platsspecifik information om staden, ange och hur långt händelsen från inbjudaren befinner sig. Alla platsspecifika data kan extraheras från webben. Det är där gruvdrift på webben kommer in i bilden.
Webbstruktur gruvdrift
Data från hyperlänkar som leder till olika sidor samlas in och förbereds för att upptäcka ett mönster. För att se en persons offentliga profil från en blogg eller någon annan webbsida finns det chansen att de bäddar in sina sociala medielänkar. Så informationen extraheras inte bara från en enda källa utan också från de kapslade sidorna genom hyperlänkar som är associerade med varje sida. Det finns olika algoritmer för att utföra detta. (Exempel: PageRank-algoritm)
Webbplatsbrytning:
När en webbapplikation är värd finns det många webbserverloggar som genereras om applikationens användarwebaktivitet. Dessa loggar betraktas som en rå data i gengäld meningsfulla data extraheras och mönster identifieras.
Till exempel, för alla e-handelsföretag, när de vill öka verksamhetsomfånget eller lägga till en förbättring för bättre kundupplevelse, övervakas användarens webbaktivitet genom applikationsloggarna och data mining används på den.
Webbbrytning och dataanläggning är mer eller mindre liknande tekniker men webbbrytning handlar om analys på webben. Data mining är inte begränsat till webben. Det är en traditionell process som sker för all dataanalys.
Prata om data från webben, det finns olika data som kan observeras. Det kan vara strukturerade data (databasdata dras genom API om de släpps för allmänheten). Semistrukturerad data - alla webbaktivitetsrelaterade eller till och med serverloggar. Eller till och med ostrukturerade data som bilder etc. (om någon analys utförs på bilder)
Jämförelse mellan head-to-head-jämförelse mellan data mining vs web mining (Infographics)
Nedan visas de 7 bästa jämförelserna mellan data mining och web mining

Viktiga skillnader mellan gruvdrift mot webbbrytning
Följande är skillnaden mellan data mining och web mining är följande
Webbbrytning och dataanläggning är båda nästan lika när det gäller att identifiera mönstren. Men var och vad är skillnaden i gruvdrift på webben från datakommunikationen. Vilken typ av data och data utvinns från var? Det här är de två ultimata aspekterna som ger skillnaden mellan Data mining och Web mining.
Webbbrytning omfattas av data mining men detta är begränsat till webbrelaterad data och identifiering av mönstren. Data mining är ett stort koncept som involverar flera steg från att förbereda data till validering av slutresultaten som leder till beslutsprocessen för en organisation.
Data mining vs web mining jämförelsetabell
| Grund för jämförelse | Data mining | Webbbrytning |
| Begrepp | Mönsteridentifiering från data tillgängliga i alla system. | Mönsteridentifiering från webbdata. |
| Ansökan / användningsfall | Väderprognos med historiska väderrapporter | Datacrypning HITS / PageRank-tekniker |
| Vem gör det här? | Datavetare Dataingenjörer | Datavetare / Dataanalytiker Dataingenjörer |
| Bearbeta | Datauttag -> Mönsterupptäckt -> Utveckla funktionen / lösa den (algoritm) | Samma process men på webben med webbdokumenten |
| Verktyg | Maskininlärningsalgoritmer | Scrappy, Pagerank, Apache-loggar |
| Hur betydelsefullt | Många organisationer förlitar sig på datavetenskapliga resultat för beslutsfattande. | Webbrelaterad datatrafik skulle påverka den befintliga dataanvinningsprocessen. |
| Kompetens | Datarengöringstekniker, maskininlärningsalgoritmer, statistik, sannolikhet | Kunskap på applikationsnivå, Datateknik, statistik, sannolikhet |
Slutsats - Data mining vs web mining
Alla gruvtekniker med uppgifterna är att upptäcka kunskapen och hur väl den kan användas för att uppnå ett bättre resultat. Organisationer som är angelägna om att förbättra sina företag och göra en hög vinst, de behöver många beslut att fatta baserat på de uppgifter som till stor del finns tillgängliga i deras system genererade i en enorm volym. Inte all information anses ge kunskap och insikter. Vilka, varför och vilka är de viktigaste frågorna som forskare / dataanalytiker måste tänka på när de förbereder sig för att identifiera mönstren. På en väldigt lekmannstid är datainsamling som en process för att riva mjölken till smör.
Rekommenderad artikel
Detta har varit en guide till dataanvinning vs webbbrytning, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Data Mining Vs Statistics - Vilken som är bättre
- 10 kraftfulla steg för effektiv planering av webbdesign
- Data mining kontra maskininlärning - 10 bästa saker du behöver veta
- De bästa tre sakerna att lära sig om datavyte kontra textbrytning
- Verktyg och tekniker som används vid dataanläggning