
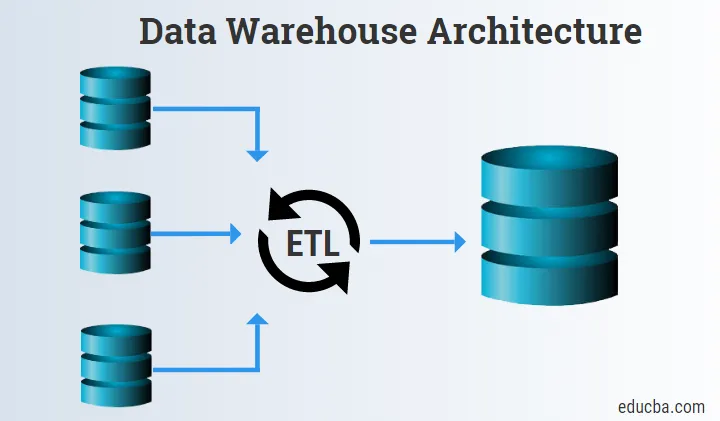
Introduktion till datalagerarkitektur
- Ett datavarehus är en lagringsplats som innehåller samlingar av flera olika typer av data som skaffats från flera typer av källor.
- Hela processen där externa datakällor förvärvas, bearbetas, lagras och analyseras till användbar information sker inom en uppsättning system som förenas av ett enda schema känt som Data Warehouse Architecture.
Datavarehusarkitektur

Datavarehusarkitekturen består vanligtvis av tre nivåer.
- Toppskiktet
- Mellannivå
- Nedre nivå
Toppskiktet
- Top Tier består av klientens främre ände av arkitekturen.
- Den transformerade och logiska tillämpade informationen som lagras i Data Warehouse kommer att användas och förvärvas för affärsändamål på detta nivå.
- Flera verktyg för rapportgenerering och analys finns för generering av önskad information.
- Data mining som har blivit en stor trend idag görs här.
- All dokumentation, kostnad och alla funktioner som bestämmer ett vinstbaserat affärsavtal görs baserat på dessa verktyg som använder Data Warehouse-informationen.
Mellannivå
- Mellannivån består av OLAP-servrar
- OLAP är online analytisk processerserver
- OLAP används för att tillhandahålla information till affärsanalytiker och chefer
- Eftersom den ligger i mellersta nivån, interagerar den med rätta med informationen som finns i bottennivån och vidarebefordrar insikten till Top Tier-verktygen som bearbetar tillgänglig information.
- Oftast används Relational eller MultiDimensional OLAP i datalagerarkitektur.
Nedre nivå
Bottennivån består huvudsakligen av datakällorna, ETL-verktyget och datavarehuset.
1. Datakällor
Datakällorna består av källdata som skaffas och tillhandahålls Staging och ETL-verktygen för vidare process.
2. ETL-verktyg
- ETL-verktyg är mycket viktiga eftersom de hjälper till att kombinera Logic, Raw Data och Schema till ett och laddar informationen till Data Warehouse eller Data Marts.
- Ibland läser ETL in data i datamärkena och sedan lagras information i datavarehus. Denna metod är känd som Bottom Up-metoden.
- Tillvägagångssättet där ETL laddar information till Data Warehouse direkt kallas Top-down Approach.
Skillnaden mellan ovanifrån och ner och upp
| Uppifrån-ner-strategi | Nedifrån-upp-strategi |
| Ger en bestämd och konsekvent bild av information eftersom information från datalageret används för att skapa datamärken | Rapporter kan enkelt genereras när datamarker skapas först och det är relativt enkelt att interagera med datamarkeringar. |
| Stark modell och därmed föredragen av stora företag | Inte lika starkt men datalager kan utökas och antalet datamarter kan skapas |
| Tid, kostnad och underhåll är hög | Tid, kostnad och underhåll är låga. |
Data Marts
- Data Mart är också en lagringskomponent som används för att lagra data för en specifik funktion eller del relaterad till ett företag av en enskild myndighet.
- Data mart samlar in informationen från Data Warehouse och därmed kan vi säga att data mart lagrar delmängden av information i Data Warehouse.
- Data Marts är flexibla och små i storlek.
3. Data Warehouse
- Data Warehouse är den centrala komponenten i hela Data Warehouse-arkitekturen.
- Det fungerar som ett arkiv för att lagra information.
- Stora datamängder lagras i Data Warehouse.
- Denna information används av flera tekniker som Big Data som kräver analys av stora underuppsättningar av information.
- Data Mart är också en modell av Data Warehouse.
Olika lager av datalagerarkitektur
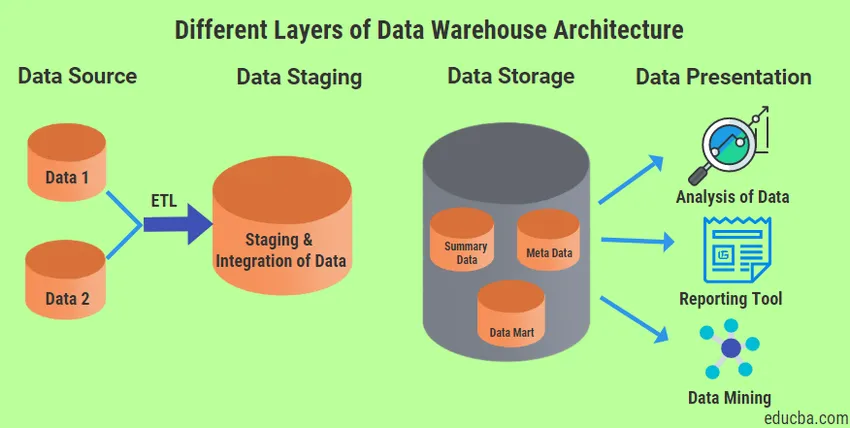
Det finns fyra olika typer av lager som alltid kommer att finnas i Data Warehouse Architecture.
1. Datakällskikt
- Datakällskiktet är det lager där data från källan stöter på och sedan skickas till de andra lagren för önskad operation.
- Uppgifterna kan vara av alla slag.
- Källdata kan vara en databas, ett kalkylblad eller någon annan typ av textfil.
- Källdata kan vara av vilket format som helst. Vi kan inte förvänta oss att få data med samma format med tanke på att källorna är väldigt olika.
- I verkliga livet kan några exempel på källdata vara
- Loggfiler för varje specifik applikation eller jobb eller inträde av arbetsgivare i ett företag.
- Undersökningsdata, börsuppgifter, etc.
- Webbläsardata och många fler.
2. Data Staging Layer
Följande steg sker i Data Staging Layer.
1. Datauttag
Data som mottagits av källlagret matas in i sceneringslagret där den första processen som sker med den förvärvade informationen är extraktion.
2. Landningsdatabas
- De extraherade data lagras tillfälligt i en landningsdatabas.
- Den hämtar data när data har extraherats.
3. Sceneringsområde
- Data i landningsdatabasen tas och flera kvalitetskontroller och iscensättningar utförs i iscenesättningsområdet.
- Strukturen och schemat identifieras också och justeringar görs för data som inte är ordnade, vilket försöker åstadkomma en gemensamhet mellan de data som har förvärvats.
- Att ha en plats eller konfigurera för data precis före omvandling och förändringar är en extra fördel som gör Staging-processen mycket viktig.
- Det gör databehandlingen enklare.
4. ETL
- Det är en extraktion, transformation och belastning.
- ETL-verktyg används för integration och bearbetning av data där logik tillämpas på ganska rå men något ordnade data.
- Dessa data extraheras enligt den analytiska karaktär som krävs och omvandlas till data som anses vara lämpliga för att lagras i datavarehuset.
- Efter transformation laddas slutligen data eller snarare en information till datalageret.
- Några exempel på ETL-verktyg är Informatica, SSIS, etc.
3. Datalagringslager
- Den bearbetade informationen lagras i Data Warehouse.
- Dessa data rengörs, omvandlas och förbereds med en bestämd struktur och ger därmed möjligheter för arbetsgivare att använda data enligt verksamheten.
- Beroende på arkitekturens tillvägagångssätt lagras data i Data Warehouse såväl som Data Marts. Data Marts kommer att diskuteras i de senare stadierna.
- Vissa inkluderar också en operationell datalager.
4. Datapresentationslager
- Detta lager där användarna får interagera med data lagrade i datalageret.
- Frågor och flera verktyg kommer att användas för att få olika typer av information baserat på uppgifterna.
- Informationen når användaren genom den grafiska representationen av data.
- Rapporteringsverktyg används för att få affärsdata och affärslogik används också för att samla in flera typer av information.
- Metadatainformation och systemoperationer och prestanda upprätthålls och ses också i detta lager.
Slutsats
En viktig punkt om Data Warehouse är dess effektivitet. För att skapa ett effektivt datavarehus konstruerar vi en ram som kallas affärsanalysramen. Det finns fyra typer av åsikter när det gäller utformningen av ett datalager.
1. Ovanifrån: Denna vy tillåter endast specifik information som behövs för att välja ett datalager.
2. Datakällvy: Den här vyn visar all information från datakällan till hur den transformeras och lagras.
3. Datavarehusvy: Denna vy visar informationen som finns i datalageret genom faktatabeller och dimensionstabeller.
4. Business Query View: Detta är en vy som visar data från användarens synvinkel.
Rekommenderade artiklar
Detta har varit en guide till Data Warehouse Architecture. Här diskuterade vi olika typer av vyer, lager och nivåer av datavarehusarkitektur. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Karriär inom datalagring
- Hur JavaScript fungerar
- Datavarehus Intervjufrågor
- Vad är Pandas