

Introduktion till svinkommandon
Apache Pig ett verktyg / plattform som används för att analysera stora datasätt och utföra långa serier av datoperationer. Gris används tillsammans med Hadoop. Alla grisskript internt konverteras till kartminskande uppgifter och körs sedan. Den kan hantera strukturerade, semistrukturerade och ostrukturerade data. Grisaffärer, dess resultat i HDFS. I den här artikeln lär vi oss fler typer av svinkommandon.
Här är några egenskaper hos Pig:
- Självoptimering: Gris kan optimera exekveringsjobb, användaren har friheten att fokusera på semantik.
- Enkel att programmera: Pig tillhandahåller språk / dialekt på hög nivå känd som Pig Latin, vilket är lätt att skriva. Pig Latin tillhandahåller många operatörer som programmerare kan använda för att bearbeta data. Programmeraren har också flexibiliteten att skriva sina egna funktioner.
- Extensible: Pig underlättar skapandet av anpassad funktion som kallas UDF: er (användardefinierade funktioner), vilket gör programmerare kapabla att uppnå alla processbehov snabbt och enkelt. Grisskriptet körs på ett skal som kallas grynningen.
Varför svinkommandon?
Programmerare som inte är bra med Java, kämpar vanligtvis med att skriva program i Hadoop, dvs att skriva kartdämpande uppgifter. För dem är Pig Latin som är ganska som SQL-språk en välsignelse. Dess flerfrågeställning minskar kodens längd.
Så totalt sett är det kortfattade och effektiva sättet att programmera. Pig-kommandon kan åberopa kod på många språk som JRuby, Jython och Java.
Arkitekturen för Pig Commands
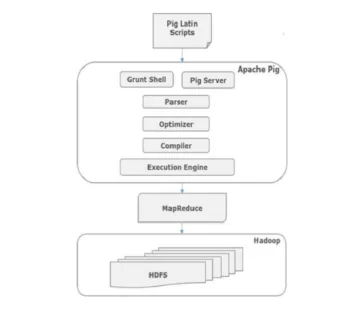
Alla skript skrivna i gris-latin över grymskal går till parsaren för att kontrollera syntaxen och andra diverse kontroller händer också. Analyserns utgång är en DAG. Denna DAG överförs sedan till Optimizer, som sedan utför logisk optimering, t.ex. projektion och trycker ner. Sedan följer kompilatorn den logiska planen till MapReduce-jobb. Slutligen skickas dessa MapReduce-jobb till Hadoop i sorterad ordning. Dessa jobb utförs och ger önskade resultat.
Pig-Latin datamodell är helt kapslad, och det tillåter komplexa datatyper som karta och tupel.
Varje enskilt värde på gris latinska språk (oavsett datatyp) kallas Atom.
Grundläggande svinkommandon
Låt oss ta en titt på några av de grundläggande gris-kommandona som ges nedan: -
1. Fs: Här listas alla filer i HDFS
gryta> fs –ls
2. Rensa: Detta kommer att rensa det interaktiva Grunt-skalet.
gryta> klar
3. Historia:
Detta kommando visar kommandona som hittills har utförts.
gryta> historia
4. Läsa data: Förutsatt att uppgifterna finns i HDFS, och vi måste läsa data till Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
ANVÄNDER PigStorage (', ')
som (id: int, förnamn: chararray, efternamn: chararray, telefon: chararray,
stad: chararray);
PigStorage () är den funktion som laddar och lagrar data som strukturerade textfiler.
5. Lagring av data: Lagra operatör används för att lagra bearbetade / laddade data.
grunt> LAGRA college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Här är “/ pig_Output /” den katalog där relationen måste lagras.
6. Dump Operator: Detta kommando används för att visa resultaten på skärmen. Det hjälper vanligtvis vid felsökning.
grunt> Dump college_studenter;
7. Beskriv operatör: Det hjälper programmeraren att se relationens schema.
grunt> beskriv college_studenter;
8. Förklara: Det här kommandot hjälper till att granska de logiska, fysiska och kartminskande exekveringsplanerna.
gryta> förklara college_studenter;
9. Illustrera operatören: Detta ger steg-för-steg exekvering av uttalanden i svinkommandon.
gryta> illustrera college_studenter;
Mellanstora svinkommandon
1. Grupp: Detta Pig-kommando fungerar mot att gruppera data med samma nyckel.
grunt> group_data = GROUP college_students med förnamn;
2. SAGROUP: Det fungerar på samma sätt som gruppoperatören. Den huvudsakliga skillnaden mellan Group & Cogroup-operatören är den gruppoperatör som vanligtvis används med en relation, medan cogroup används med mer än en relation.
3. Gå med: Detta används för att kombinera två eller flera relationer.
Exempel: För att utföra självförening, låt oss säga att relation "kund" laddas från HDFS tp-svinkommandon i två relationer kunder1 & kunder2.
gryta> kunder3 = GÅ MED kunder1 BY ID, kunder2 BY ID;
Gå med kan vara självförening, Inre-gå, Yttre-gå.
4. Kors: Detta griskommando beräknar korsprodukten för två eller flera relationer.
grunt> cross_data = CROSS kunder, beställningar;
5. Union: Det slås samman två förbindelser. Villkoret för sammanslagning är att både relationens kolumner och domäner måste vara identiska.
gryn> student = UNION student1, student2;
Avancerade svinkommandon
Låt oss ta en titt på några av de avancerade svin-kommandona som ges nedan:
1. Filter: Detta hjälper till att filtrera ut tuplorna ur relation, baserat på vissa villkor.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinct: Detta hjälper till att ta bort redundanta tuplor från relationen.
gryn> distinkta data = DISTINCT college_studenter;
Denna filtrering skapar ett nytt förhållande namn "distinkta_data"
3. Foreach: Detta hjälper till att generera datatransformation baserad på kolumndata.
grunt> foreach_data = FOREACH student_detaljer GENERERA ID, ålder, stad;
Detta kommer att få id, ålder och stadsvärden för varje student från relationen studentdetaljer och kommer därför att lagra den i en annan relation med namnet foreach_data.
4. Order efter: Detta kommando visar resultatet i en sorterad ordning baserad på ett eller flera fält.
grunt> order_by_data = BESTÄLL college_studenter per ålder DESC;
Detta kommer att sortera relationen "college_students" i fallande ordning efter ålder.
5. Begränsning: Det här kommandot blir begränsat nr. av tuples från förhållandet.
grunt> limit_data = LIMIT student_detaljer 4;
Tips och tricks
Nedan finns de olika tips och tricks med svinkommandon: -
1. Aktivera komprimering på din ingång och utgång:
ställa input.compression.enabled sant;
ställa output.compression.enabled sant;
Ovan nämnda kodrader måste vara i början av skriptet, så att Pig-kommandon kan läsa komprimerade filer eller generera komprimerade filer som utgång.
2. Gå med i flera relationer:
För att utföra vänster sammanfogning på säga tre relationer (input1, input2, input3), måste man välja SQL. Det beror på att yttre sammanfogning inte stöds av Pig på mer än två bord.
Snarare utför du vänster för att gå med i två steg som:
data1 = JOIN input1 BY key VÄNSTER, input2 BY key;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Detta betyder två kartminskande jobb.
För att utföra ovanstående uppgift mer effektivt kan man välja “Cogroup”. Cogroup kan gå med i flera relationer. Cogroup som standard går yttre samman.
Slutsats
Gris är ett procedurspråk, som vanligtvis används av datavetare för att utföra ad-hoc-behandling och snabb prototypning. Det är ett fantastiskt ETL och stor databehandlingsverktyg. Grisskript kan åberopas av andra språk och vice versa. Därför kan svinkommandon användas för att bygga större och komplexa applikationer.
Rekommenderade artiklar
Detta har varit en guide till svinkommandon. Här har vi diskuterat såväl grundläggande som avancerade svinkommandon och några omedelbara svinkommandon. Du kan också titta på följande artikel för att lära dig mer -
- Adobe Photoshop-kommandon
- Tableau-kommandon
- Fuskark SQL (kommandon, gratis tips och trick)
- VBA-kommandon - efterbehandling
- Olika operationer relaterade till tuples