

Introduktion till metoder för utvinning av data
Data ökar dagligen i en enorm skala. Men all information som samlas in eller samlas är inte användbar. Meningsfulla data måste separeras från bullriga data (meningslösa data). Denna process för separering görs av data mining.
Vad är Data Mining?
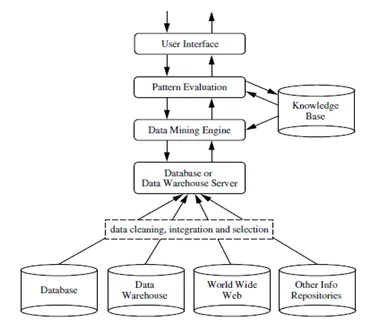
Data mining är en process för att extrahera användbar information eller kunskap från en enorm mängd data (eller big data). Klyftan mellan data och information har reducerats med hjälp av olika data mining-verktyg. Data mining kan också kallas kunskapsupptäckt från data eller KDD .
Källor: - www.ques10.com
Data mining kan utföras på olika typer av databaser och informationslager som relationsdatabaser, datalager, transaktionsdatabaser, dataströmmar och många fler.
Olika metod för gruvdrift:
Det finns många metoder som används för Data Mining, men det avgörande steget är att välja lämplig metod från dem beroende på verksamheten eller problemet. Dessa metoder för datainsamling hjälper till att förutsäga framtiden och sedan fatta beslut i enlighet därmed. Dessa hjälper också till att analysera marknadsutvecklingen och öka företagens intäkter.
Vissa metoder för datainrinning är:
- Förening
- Klassificering
- Klusteranalys
- Förutsägelse
- Sekventiella mönster eller mönsterspårning
- Beslutsträd
- Utvärderingsanalys eller anomalysanalys
- Neuralt nätverk
Låt oss förstå alla metoder för datainsamling en efter en.
1. Förening:
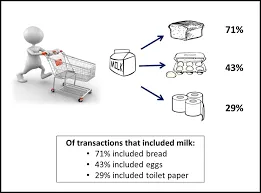
Det är en metod som används för att hitta en korrelation mellan två eller flera objekt genom att identifiera det dolda mönstret i datauppsättningen och därmed också kallas som relationsanalys . Denna metod används i marknadskorganalys för att förutsäga kundens beteende.
Antag att marknadschefen i en stormarknad vill bestämma vilka produkter som ofta köps tillsammans.
Som ett exempel,
Köper (x, "öl") -> köper (x, "chips") (stöd = 1%, förtroende = 50%)
- Här representerar x en kund som köper öl och chips tillsammans.
- Förtroende visar visshet om att om en kund köper en öl finns det 50% chans att han / hon också köper chips.
- Stöd innebär att 1% av alla transaktioner som analyserades visade att öl och chips köptes tillsammans.
Många liknande exempel som bröd och smör eller dator och programvara kan övervägas.
Det finns två typer av associeringsregler:
- Enkel dimensionell associeringsregel: Dessa regler innehåller ett enda attribut som upprepas.
- Multidimensionell associeringsregel: Dessa regler innehåller flera attribut som upprepas.
https://bit.ly/2N61gzR
2. Klassificering:
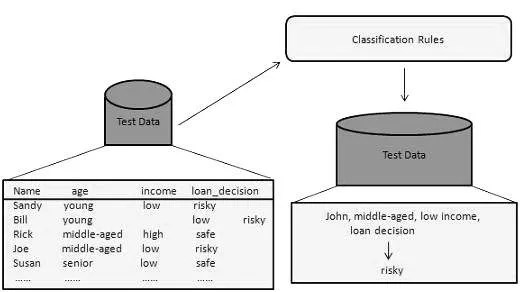
Denna metod för gruvdrift används för att skilja objekt i datauppsättningarna i klasser eller grupper. Det hjälper dig att förutsäga exakt beteende hos objekt inom gruppen. Det är en tvåstegsprocess:
- Inlärningssteg (träningsfas): I detta bygger en klassificeringsalgoritm klassificeringen genom att analysera en träningsuppsättning.
- Klassificeringssteg: Testdata används för att uppskatta klassificeringsreglernas noggrannhet eller precision.
Till exempel använder ett bankföretag för att identifiera lånesökande med låg, medelhög eller hög kreditrisk. På liknande sätt analyserar en medicinsk forskare cancerdata för att förutsäga vilket läkemedel som ska förskrivas till patienten.
Källor: - www.tutorialspoint.com
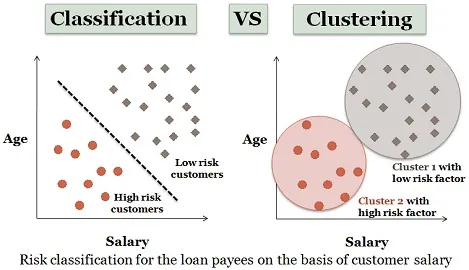
3. Clustering-analys:
Clustering är nästan lik klassificering men i denna kluster görs beroende på likheterna med dataobjekt. Olika kluster har olika eller oberoende föremål. Det kallas också som datasegmentering eftersom det delar upp enorma datamängder i kluster beroende på likheter.
Det finns olika klusteringsmetoder som används:
- Hierarkiska agglomerativa metoder
- Rasterbaserade metoder
- Partitionsmetoder
- Modellbaserade metoder
- Täthetsbaserade metoder
Liknande exempel på lånesökande kan också ses här. Det finns några skillnader som visas i figuren nedan.
https://bit.ly/2N6aZpP
4. Förutsägelse:
Denna metod används för att förutsäga framtiden baserat på tidigare och nuvarande trender eller datauppsättning. Förutsägelse används mest med kombinationen av andra data mining metoder, såsom klassificering, mönster matchning, trendanalys och relation.
Om till exempel försäljningschefen i en stormarknad vill förutsäga hur stora intäkter varje objekt skulle generera baserat på tidigare försäljningsdata. Den modellerar kontinuerlig värderad funktion som förutsäger saknade numeriska datavärden.

Källor: - data-mining.philippe-fournier
Regressionsanalys är det bästa valet att utföra förutsägelse. Det kan användas för att ställa in en relation mellan oberoende variabler och beroende variabler.
5. Sekvensmönster eller mönsterspårning:
Denna datamining metod används för att identifiera mönster som uppstår ofta under en viss tidsperiod.
Till exempel ser försäljningschefen för klädföretag att försäljningen av jackor verkar öka strax före vintersäsongen, eller försäljningen i bageriet ökar under jul eller nyårsafton.
Låt oss titta på ett exempel med en graf
Källor: - data-mining.philippe-fournier-viger
6. Beslutsträd:
Ett beslutsträd är en trädstruktur (som namnet antyder), var
- Varje intern nod representerar ett test på attributet.
- Filialen anger resultatet av testet.
- Terminalnoder har klassetiketten.
- Den översta noden är rotnoden som har den enkla frågan som har två eller flera svar. Följaktligen växer trädet och ett flödesschema-liknande struktur genereras.
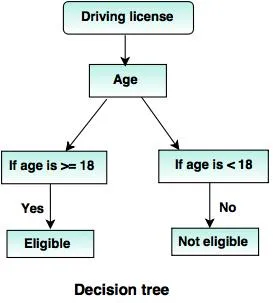
Källor: - www.tutorialride.com
I detta beslut klassificerar trädregeringen medborgare under 18 år eller över 18 år. Detta skulle hjälpa dem att avgöra om en licens måste utfärdas till en viss medborgare eller inte.
7.Outlier analys eller anomaly analys:
Denna metod för utvinning av data används för att identifiera dataposter som inte överensstämmer med det förväntade mönstret eller förväntade beteenden. Dessa oväntade dataobjekt betraktas som outliers eller buller. De är användbara på många domäner, som upptäckt av kreditkortsbedrägerier, intrångsdetektering, feldetektering etc. Detta kallas också för Outlier Mining .
Låt oss till exempel anta att diagrammet nedan är ritat med vissa datauppsättningar i vår databas.
Så den bästa passningslinjen dras. De punkter som ligger i närheten av linjen visar förväntat beteende medan punkten långt från linjen är en Outlier.
Detta skulle hjälpa till att upptäcka avvikelserna och vidta möjliga åtgärder i enlighet därmed.
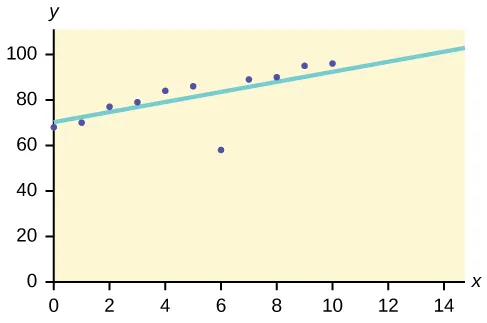
https://bit.ly/2GrgjDP
8. Neurala nätverk:
Denna metod eller modell för datainsamling är baserad på biologiska neurala nätverk. Det är en samling neuroner som behandlingsenheter med viktade förbindelser mellan dem. De används för att modellera förhållandet mellan ingångar och utgångar. Den används för klassificering, regressionsanalys, databehandling etc. Denna teknik fungerar på tre pelare-
- Modell
- Lärande algoritm (övervakad eller utan tillsyn)
- Aktiveringsfunktion
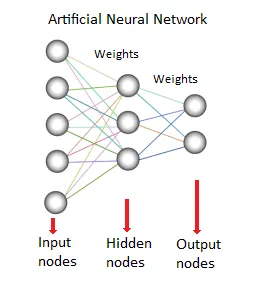
Källor: - www.saedsayad.com
Rekommenderade artiklar
Detta har varit en guide till Metod för gruvdrift Här har vi diskuterat Vad är datakommunikation och olika typer av datakommunikationsmetod med exemplet. Du kan också titta på följande artiklar för att lära dig mer -
- Big Data Analytics-programvara
- Informationsstrukturintervjufrågor
- Viktiga data gruvtekniker
- Data Mining Architecture