

Splunk intervjufrågor och svar - introduktion
Så du har äntligen hittat ditt drömjobb i Splunk men undrar hur du kan knäcka Splunkintervju och vad som kan vara de troliga frågorna om Splunkintervju för 2018. Varje intervju är annorlunda och omfattningen av ett jobb är också annorlunda. Med detta i åtanke har vi utformat de vanligaste Splunkintervjufrågor och svar för 2018 för att hjälpa dig att få framgång i din intervju.Nedan visas de mest användbara Splunk-intervjufrågorna och svaret. Dessa toppfrågor är indelade i två delar är följande:
Del 1 - Splunk intervjufrågor (grundläggande)
Den första delen täcker grundläggande Splunkintervjufrågor och svar.
1. Vad är Splunk? Varför används Splunk för att analysera maskindata?
Svar:
Ett av de mest använda analysverktygen där ute är Microsoft Excel och nackdelen med det är att Excel bara kan ladda upp till 1048576 rader och maskindata är i allmänhet enorma. Splunk är praktiskt när det gäller att hantera maskingenererade data (big data), data från servrar, enheter eller nätverk kan enkelt laddas in i Splunk och kan analyseras för att kontrollera om det finns hot om synlighet, efterlevnad, säkerhet etc. det kan också användas för övervakning av applikationer.
2. Förklara hur Splunk fungerar
Svar:
Detta är de vanliga Splunkintervjufrågor som ställs i en intervju. Data laddas in i Splunk med hjälp av vidarebefordran som fungerar som ett gränssnitt mellan Splunk-miljön och omvärlden, och därefter vidarebefordras dessa data till en indexerare där data antingen lagras lokalt eller på ett moln. Indexatorn indexerar maskindata och lagrar dem på servern. Search Head är GUI som tillhandahålls av Splunk för att söka och analysera (söker, visualiserar, analyserar och utför olika andra funktioner) data.
Distributionsserver hanterar alla komponenter i Splunk som indexerare, speditör och sökhuvud i Splunk-miljön. 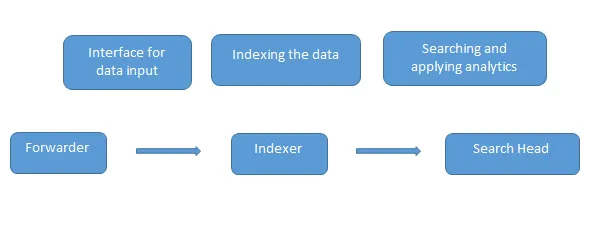
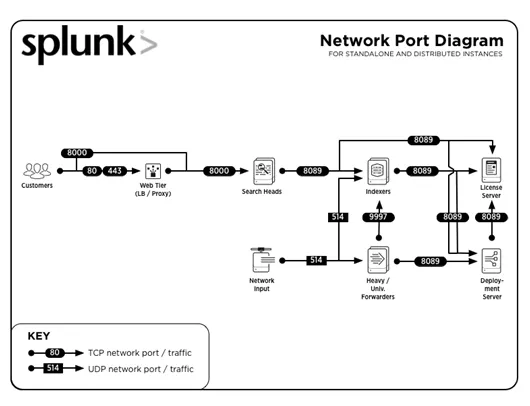
3. Vad är vanliga portnummer som används av Splunk?
Svar :
Vanliga portnummer där tjänster körs (som standard) är:
| Service | Portnummer |
| Management / REST API | 8089 |
| Sökhuvud / indexerare | 8000 |
| Sök huvud | 8065, 8191 |
| Indexer kluster peer node / Sökhuvud kluster medlem | 9887 |
| Indexer | 9997 |
| Indexer / Transport | 514 |
Låt oss gå till nästa Splunk-intervjufrågor.
4. Varför använda bara Splunk?
Svar:
Det finns många alternativ för Splunk som ger mycket konkurrens för det, några av dem är som nedan:
• ELK / Logstash (öppen källkod)
Elasticsearch används för att söka, det är som sökhuvudet i Splunk, Log stash är för datainsamling som liknar speditören som används i Splunk, och Kibana används för datavisualisering (sökhuvudet gör samma sak i Splunk)
• Graylog (öppen källkod med kommersiell version)
Graylog är ännu ett verktyg som fick namnet förra året med lanseringen 1.0. I likhet med ELK-stacken har Graylog också olika komponenter som den använder Elasticsearch som sin kärnkomponent men data lagras i Mongo DB och använder Apache Kafka. Den har två versioner, en kärnversion som är tillgänglig gratis och företagsversionen som har funktioner som arkivering.
• Sumo Logic (molntjänst)
Så det som gör Splunk bäst bland allt är att Splunk kommer som ett enda paket med datainsamlaren, lagring och det inbyggda analysverktyget. Splunk är också skalbar och ger support / professionell hjälp för sin företagsutgåva.
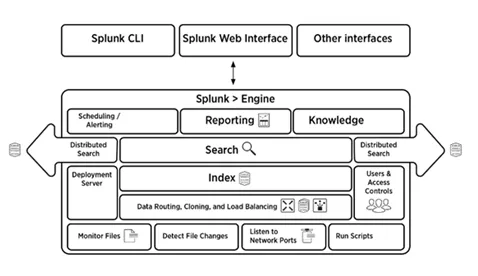
5. Förklara kortfattat arkitekturen
Svar:
Bilden nedan ger en kort överblick över Splunk-arkitekturen och dess komponenter.
Del 2 - Splunkta intervjufrågor (Avancerat)
Låt oss nu titta på de avancerade frågorna om Splunk-intervjuer.
6. Vad är komponenterna i Splunk-arkitekturen?
Svar:
Det finns fyra komponenter i Splunk-arkitekturen. Dom är:
- Indexer: Indexerar maskindata
- Speditör: Vidarebefordrar loggar till index
- Sökhuvud: Ger GUI för sökning
- Distributionsserver: Hanterar Splunk-komponenterna (indexerare, speditör och sökhuvud) i en distribuerad miljö
7. Ge några användningsfall av kunskapsobjekt.
Svar :
Detta är de vanliga frågorna om Splunk-intervjuerna i en intervju. Kunskapsobjekt kan användas i många domäner. Några exempel är:
Applikationsövervakning: Detta kan användas för att övervaka applikationer i realtid med konfigurerade varningar som meddelar administratörer / användare när en applikation kraschar.
Fysisk säkerhet: I händelse av en översvämning / vulkan etc kan data användas för att få insikter om din organisation har att göra med sådana uppgifter.
Nätverkssäkerhet: Du kan skapa en säker miljö genom att svartlista IP: n av okända enheter och därmed minska dataläckage i alla organisationer.
Medarbetarnas ledning: Arbetstagarnas utmattning är en av de utmaningar som någon organisation står inför och under uppsägningstiden kan den anställdas aktivitet spåras för att skydda organisationens uppgifter och därmed övervaka deras aktivitet och begränsa någon annan anställd i uppsägningstiden att inte göra samma sak .
8.Explain Search Factor (SF) & Replication Factor (RF)
Svar:
Dessa är terminologierna som används i Splunk-klusteringstekniker. Indexer-klustret är en speciellt konfigurerad grupp av Splunk Enterprise-indexerare som replikerar extern data och används för katastrofåterställning.
När det gäller sökningen av Splunk-dokumentationen kan faktorn beskrivas som ”Antalet sökbara kopior av data som ett indexeringskluster upprätthåller. Standardfaktorn för sökfaktorn är 2 ”medan replikationsfaktorn definieras som antalet kopior av data som klustret upprätthåller.
Indexer-klustret har både en sökfaktor och en replikeringsfaktor medan sökhuvudklustret endast har en sökfaktor
Låt oss gå till nästa Splunk-intervjufrågor.
9. Vad är Splunk hinkar? Förklara hinkens livscykel.
Svar:
De kataloger där de indexerade data lagras är kända som Splunk-hinkar och dessa har händelser under en viss period. Livslängden på Splunk-hinken inkluderar fyra steg varma, varma, kalla, frysta och tinade.
- Hot - Den här hinken innehåller de nyligen indexerade data och är öppen för skrivning.
- Varmt - Efter att data har fallit i het hink beroende på dina datapolicys flyttas de till varma skopor
- Kallt - Nästa steg efter värme är det kalla steget där data inte kan redigeras.
- Frozen - Som standard raderar indexeraren data från frysta skopor men dessa kan också arkiveras.
- Tina - Hämtning av information från arkiverade filer (frusen hink) kallas tining.
10. Varför ska vi använda Splunk Alert? Vilka är de olika alternativen när du ställer in varningar?
Svar:
Tillståndet att vara vaken för eventuella fel kallas larm och i Splunk kan miljövarningar uppstå på grund av eventuella anslutningsfel eller säkerhetsöverträdelser eller brott av användarskapade regler.
Till exempel skicka aviseringar eller en rapport från de användare som inte har loggat in efter att ha använt sina tre försök i en portal till applikationsadministratören.
Olika alternativ som är tillgängliga vid inställning av varningar är:
- En webhook kan skapas för att skriva varningar till hipchat eller GitHub.
- Lägg till resultat, .csv eller pdf eller i linje med meddelandets huvuddel så att orsaken till varningen kan identifieras.
- Biljetter kan skapas och varningar kan strypas från en maskin eller en IP.
Rekommenderad artikel
Detta har varit en guide till Lista över Splunkintervjufrågor och svar så att kandidaten lätt kan slå ned dessa Splunkintervjufrågor och svar. Du kan också titta på följande artikel för att lära dig mer -
- SAS Systemintervjufrågor - Topp 10 användbara frågor
- 10 utmärkta Tableauintervjufrågor du måste veta
- 15 mest framgångsrika frågor och svar på Oracle-intervjuer
- Nätverkssäkerhetsintervjufrågor - Topp och mest ställda
- Splunk vs Nagios