
Skillnaden mellan Hive och HBase
Apache Hive och HBase är Hadoop-baserade big data-teknologier. De brukade båda fråga data. Hive och HBase kör ovanpå Hadoop och de skiljer sig åt i sin funktionalitet. Hive är kartreducerad baserad SQL-dialekt medan HBase endast stöder MapReduce. HBase lagrar data i form av nyckel / värde eller kolumnfamiljpar medan Hive inte lagrar data.
Head to Head skillnader mellan Hive vs HBase (Infographics)
Nedan visas topp 8 skillnaden mellan Hive vs HBase
Viktiga skillnader mellan Hive vs HBase
- Hbase är en ACID-kompatibel medan Hive inte är det.
- Hive stöder partitionering och filterkriterier baserat på datumformatet medan HBase stöder automatiserad partitionering.
- Hive stöder inte uppdateringsförklaringar medan HBase stöder dem.
- Hbase är snabbare jämfört med Hive för att hämta data.
- Hive används för att bearbeta strukturerade data medan HBase, eftersom den är schemafri, kan behandla alla typer av data.
- Hbase är mycket (horisontellt) skalbar i jämförelse med Hive.
- Hive analyserar data på HDFS med stöd av SQL Queries och sedan konverterar de det till en karta och minskar jobb medan i Hbase eftersom det är realtidsströmning utför det direkt sina operationer i databasen genom att partitionera till tabeller och kolumnfamiljer.
- när man kommer till frågan om datakupan använder ett skal som kallas Hive shell för att utfärda kommandona medan HBase eftersom det är databas kommer vi att använda ett kommando för att bearbeta data i HBase.
- För att gå till Hive-skalet kommer vi att använda kommandokupan. Efter att ha gett detta kommer det att se ut som bikupa>. I HBase ger vi helt enkelt som Använd HBase.
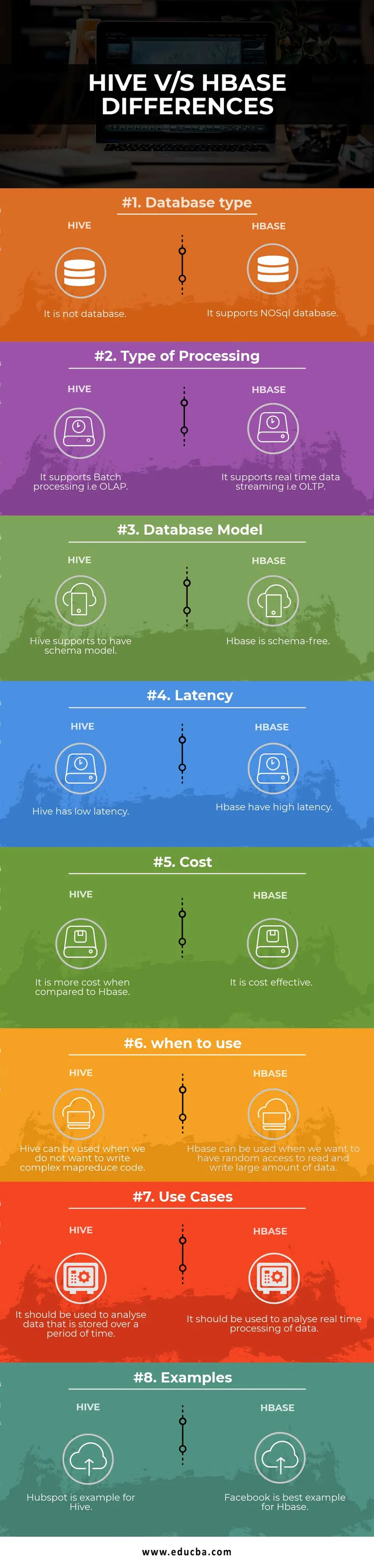
Hive vs HBase jämförelsetabell
| Grund för jämförelse | Bikupa | Hbase |
| Databastyp | Det är inte en databas | Det stöder NoSQL-databas |
| Typ av behandling | Det stöder batchbehandling dvs. OLAP | Det stöder dataströmning i realtid, dvs OLTP |
| Databasmodell | Hive stöder att ha schemamodell | Hbase är schemafri |
| Latens | Hive har låg latens | Hbase har hög latens |
| Kosta | Det är dyrare jämfört med HBase | Det är kostnadseffektivt |
| när du ska använda | Hive kan användas när vi inte vill skriva komplex MapReduce-kod | HBase kan användas när vi vill ha slumpmässig åtkomst för att läsa och skriva en stor mängd data |
| Använd fall | Det bör användas för att analysera data som lagras under en tidsperiod | Det bör användas för att analysera data i realtid. |
| exempel | Hubspot är ett exempel för Hive | Facebook är det bästa exemplet för Hbase |
Skillnader i kodning mellan Hive vs HBase
Låt oss nu diskutera de grundläggande skillnaderna mellan Hive och HBase i kodning.
| Grund för jämförelse | Bikupa | Hbase |
| Skapa en databas | SKAPA DATABASERING (OM INTE EXISTERAR) DATABASE-NAME; | Eftersom Hbase är en databas behöver vi inte skapa en specifik databas |
| För att släppa en databas | DROP DATABASE (IF EXISTS) DATABASE-NAME (RESTRICT ELLER CASCADE); | NA |
| Skapa en tabell | SKAPA (TIDIGA ELLER YTTERLIGT) BORD (OM INTE EXISTERA) TABELLNAMN ((kolumnnamn data_typ (Kommentar kolumn-kommentar), ….)) (Kommentar tabell_komment) (ROW FORMAT radformat) (lagras som filformat) | SKAPA '', '' |
| Att ändra ett bord | ALTER TABELL namn RENAME TO new-name
ALTER TABELL namn DROP (COLUMN) kolumnnamn ALTER TABELL namn ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name CHANGE kolumnnamn new-name new-type ALTER TABELL namn Byt ut kolumner (col-spec (, col-spec ..)) | ALTER 'TABELL-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Inaktivera en tabell | NA | inaktivera 'TABLE-NAME' -> för att inaktivera angivet tabellnamn
disable_all 'r *' -> för att inaktivera alla tabeller som matchar det vanliga uttrycket |
| Aktivera en tabell | NA | aktivera 'TABLE-NAME' |
| Att släppa ett bord | DROPTA TABELL OM EXISTERER tabellnamn | Om vi vill släppa ett bord måste vi först inaktivera det
inaktivera "tabellnamn" släpp "tabellnamn" På liknande sätt kan vi använda disable_all och drop_all för att ta bort tabellerna som matchar det angivna reguljära uttrycket. |
| För att lista databaser | visa databaser; | NA |
| För att lista tabeller i databasen | visa tabeller; | lista |
| För att beskriva schema för en tabell | beskriva tabellnamn; | beskriv "tabellnamn" |
Integration av Hive vs HBase
- Installera och konfigurera Hive.
- Installera och konfigurera HBase.
- För integration av både Hive och HBase använder vi STORAGE HANDLERS i Hive.
- Storage Handlers är en kombination av SERDE, InputFormat, OutputFormat som accepterar alla externa enheter som en tabell i Hive.
- Så den här funktionen hjälper en användare att utfärda SQL-frågor, oavsett om tabellen finns i Hadoop eller i NOSQL-baserad databas som HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nu kommer vi att undersöka ett exempel för att ansluta Hive med HBase med HiveStorageHandler:
- Först måste vi skapa Hbase-tabellen med kommandot.
skapa 'Student', 'personalinfo', 'dept info'
-> Personalinfo och avd. Info skapar två olika kolumnfamiljer i Studenttabellen.
- Vi måste infoga en del data i Studenttabellen. Till exempel, som nämns nedan.
sätta 'student', 'sid01 ′, ' personalinfo: namn ', ' Ram '
sätta 'student', 'sid01 ′, ' personalinfo: mailid ', ' '
sätta 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
sätta 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> På liknande sätt kan vi skapa data för sid02, sid03 …
- Nu måste vi skapa Hive-tabell som pekar på HBas-tabellen.
- För varje kolumn i Hbase kommer vi att skapa en specifik tabell för den kolumnen i Hive. I detta fall kommer vi att skapa två tabeller i Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> På liknande sätt måste vi skapa information om tabellen för avdelningsinfo i bikupan.
- Nu kan vi skriva SQL-fråga i en bikupa som nämns nedan.
select * from student_hbase;
På detta sätt kan vi integrera Hive med HBase.
Slutsats - Hive vs HBase
Som diskuterats är de båda olika tekniker som ger olika funktioner där Hive fungerar med SQL-språk och det kan också kallas som HQL och HBase använder nyckelvärdespar för att analysera data. Hive och HBase fungerar bättre om de kombineras eftersom Hive har låg latens och kan bearbeta en enorm mängd data men inte kan upprätthålla uppdaterade data och HBase stöder inte analys av data utan stöder uppdateringar på radnivå för en stor mängd av data.
Rekommenderad artikel
Detta har varit en guide till Hive vs HBase, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Apache Pig vs Apache Hive - Topp 12 användbara skillnader
- Ta reda på de 7 bästa skillnaderna mellan Hadoop vs HBase
- Topp 12 jämförelse av Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Ta reda på de bästa skillnaderna