

Introduktion till Join in Spark SQL
Som vi vet används sammanfogningarna i SQL för att kombinera data eller rader från två eller flera tabeller baserade på ett gemensamt fält mellan dem. I det här ämnet kommer vi att lära oss om Gå med i Spark SQL Gå med i Spark SQL.
I Spark SQL är Dataframe eller Dataset en tabellstruktur i minnet med rader och kolumner som är fördelade över flera noder. Liksom vanliga SQL-tabeller kan vi också utföra kopplingsoperationer på Dataframe eller Dataset som finns i Spark SQL baserat på ett gemensamt fält mellan dem.
Det finns olika typer av Gå-operationer tillgängliga i SQL. Beroende på fallet för affärsanvändning, gör vi valet av gå med. I följande avsnitt kommer vi att demonstrera varje typ av sammanfogning med exempel.
Typer av gå med i Spark SQL
Följande är de olika typerna av Joins tillgängliga i Spark SQL:
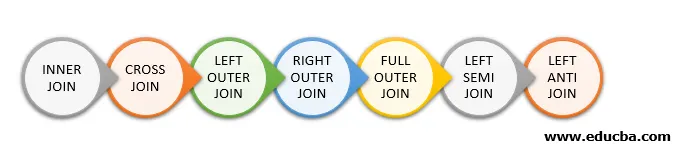
- INRE KOPPLING
- KRÄSS GÅ MED
- Vänster yttre medlem
- RIGHT OUTER JOIN
- FULL YTTERLEDNING
- Vänster SEMI GÅ MED
- Vänster ANTI GÅ MED
Exempel på datakreation
Vi kommer att använda följande data för att demonstrera de olika typerna av sammanfogningar:
Bokdataset:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer Dataset:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Typer av sammanfogningar
Nedan nämns 7 olika typer av sammanfogningar:
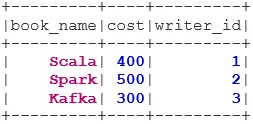
1. INNER JOIN
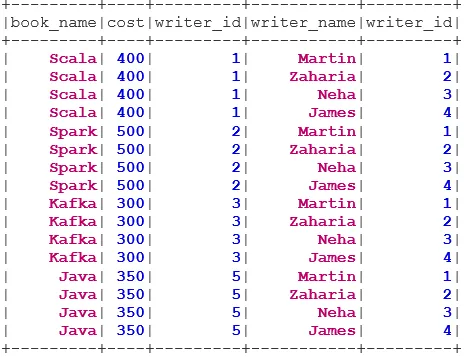
INNER JOIN returnerar datasatsen som har raderna som har matchande värden i båda datasätten, dvs värdet för det gemensamma fältet kommer att vara detsamma.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. GÅ MED GÅ
CROSS JOIN returnerar datasatsen som är antalet rader i det första datasättet multiplicerat med antalet rader i det andra datasettet. Sådant resultat kallas den kartesiska produkten.
Förutsättning: För att använda en korsning måste spark.sql.crossJoin.enabled vara inställd på true. Annars kastas undantaget.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. Vänster vänster sida
LEFT OUTER JOIN returnerar datasatsen som har alla rader från den vänstra datasatsen och de matchade raderna från den högra datasatsen.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. RÄTT YTTERLEDNING
RIGHT OUTER JOIN returnerar datasetet som har alla rader från det högra datasettet och de matchade raderna från den vänstra datasatsen.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. FULLT YTTERLEDNING
FULL OUTER JOIN returnerar datasatsen som har alla rader när det finns en matchning i antingen vänster eller höger datasats.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. Vänster SEMI GÅ MED
Vänster SEMI JOIN returnerar datasatsen som har alla rader från vänster dataset med sin korrespondens i rätt datasats. Till skillnad från LEFT OUTER JOIN innehåller det returnerade datasättet i LEFT SEMI JOIN endast kolumnerna från vänster dataset.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. Vänster ANTI GÅ MED
ANTI SEMI JOIN returnerar datasatsen som har alla raderna från den vänstra datasatsen som inte har sin matchning i rätt datasats. Den innehåller också bara kolumnerna från det vänstra datasättet.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Slutsats - Gå med i Spark SQL
Att gå med i data är en av de vanligaste och viktigaste åtgärderna för att uppfylla vårt fall för affärsanvändning. Spark SQL stöder alla grundläggande typer av sammanfogningar. När vi går med måste vi också överväga prestanda eftersom de kan kräva stora nätverksöverföringar eller till och med skapa datasätt utöver vår förmåga att hantera. För att förbättra prestanda använder Spark SQL optimizer för att ordna om eller skjuta ner filter. Gnista begränsar också den farliga sammanfogningen i. e CROSS JOIN. För att använda en cross-join måste spark.sql.crossJoin.enabled vara inställd på uttryckligen.
Rekommenderade artiklar
Detta är en guide för att gå med i Spark SQL. Här diskuterar vi de olika typerna av Joins som finns tillgängliga i Spark SQL med exemplet. Du kan också titta på följande artikel.
- Typer av sammanfogningar i SQL
- Tabell i SQL
- SQL Infoga fråga
- Transaktioner i SQL
- PHP-filter | Hur validerar man användarinmatning med olika filter?