
Skillnaden mellan Hadoop och Redshift
Hadoop är en öppen källkodsram som utvecklats av Apache Software Foundation med sina viktigaste fördelar med skalbarhet, tillförlitlighet och distribuerad datoranvändning. Databehandling, lagring, åtkomst, säkerhet är flera typer av funktioner tillgängliga i Hadoop Ecosystem. HDFS har en hög genomströmning vilket innebär att man kan hantera stora datamängder med parallellbehandlingsfunktion. Redshift är en webbhotell för molnhotell utvecklad av Amazon Web Services-enheten inom Amazon.com Inc., av de befintliga tjänster som tillhandahålls av Amazon. Det används för att designa ett storskaligt datalager i molnet. Redshift är en datalagertjänst i petabyte-skala som hanteras fullt ut och kostnadseffektivt för att driva stora datamängder.
Låt oss studera mer om Hadoop och Redshift i detalj:
Hadoop HDFS har hög feltoleransförmåga och var designad för att köra på hårdvara med låg kostnad. Hadoop kan hantera en minsta typstorlek av TeraBytes till GigaBytes av filer i sitt system. HDFS är master-slavarkitektur som består av Namnoder och Datanoder där Namnoden innehåller metadata och Datanoden innehåller verkliga data som ska bearbetas eller drivas.
RedShift använder olika datainlastningstekniker som BI (Business Intelligence) -rapportering, analysverktyg och data mining. Redshift tillhandahåller en konsol för att skapa och hantera Amazon Redshift-kluster. Kärnkomponenten i Redshift Data Warehouse är ett kluster.
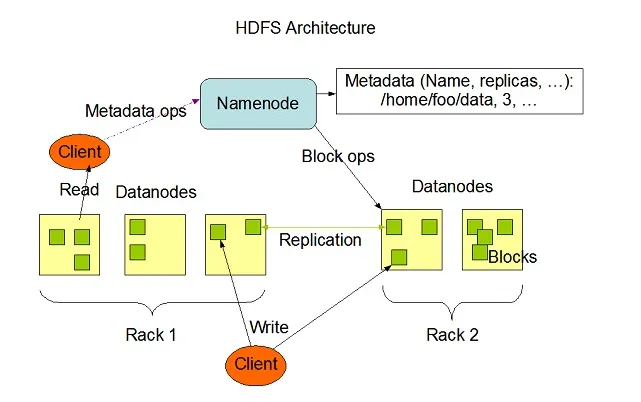
Bildkälla: Apache.org
RedShift-arkitektur:
 Bildkälla: Amazon.com
Bildkälla: Amazon.com
Head to Head Jämförelse mellan Hadoop vs Redshift (Infographics):
Nedan visas de 10 bästa jämförelserna mellan Hadoop och Redshift

Viktiga skillnader mellan Hadoop vs Redshift:
Nedan visas de viktigaste skillnaderna mellan Hadoop vs Redshift som följer
1. Arkitekturen för Hadoop HDFS (Hadoop Distribuerad filsystem) har namnnoder och datanoder, medan Redshift har Leader Node och Compute Nodes där Compute-noder kommer att delas upp som segment.
2. Hadoop tillhandahåller kommandoradgränssnitt för att interagera med filsystem medan RedShift har Management-konsol för att interagera med Amazon-lagringstjänster som S3, DynamoDB etc.,
3.Databasverksamheten ska konfigureras av utvecklare. I Redshift automatiserar databasverksamheten genom att analysera exekveringsplanerna.
4.Hadoop har flera tredjepartsverktygsstöd som enkelt kan integreras medan Redshift endast stöder de produkter som utvecklats av Amazon i sitt moln.
5. När det gäller Hadoop arkitektonisk design har nätverk, lagring, säkerhet och prestanda betraktats som primära element medan dessa i Redshift kan enkelt och flexibelt konfigureras med Amazon molnhanteringskonsol.
6.Hadoop är en filsystemarkitektur baserad på Java Application Programming Interfaces (API) medan Redshift är baserad på Relational model Database Management System (RDBMS).
7.Hadoop kan ha integrationer med olika leverantörer och Redshift har inget stöd i detta fall där Amazon är deras enda leverantör. Vad händer om en användare är missnöjd med tjänsten? I detta fall är Hadoop en fördel.
8. De flesta av de befintliga företagen använder fortfarande Hadoop medan nya kunder väljer RedShift.
9. I termer saknar prestation Hadoop alltid bakom och Redshift vinner alltid när det gäller frågautförande på stora datamängder.
10.Hadoop använder Map Reduce programmeringsmodell för att köra jobb. Amazon Redshift använder Amazons Elastic Map Reduce.
11.Hadoop använder Map Reduce programmeringsmodell för att köra jobb. Amazon Redshift använder Amazons Elastic Map Reduce.
12.Hadoop föredrar att köra batchjobb dagligen som blir billigare medan Redshift kommer ut billigare i fallet med OLAP-teknik (Online Analytical Processing) som finns bakom många Business Intelligence-verktyg.
13.Hadoop är 10 gånger långsammare än Redshift när det gäller att köra frågor på liknande sätt Hadoop är 10 gånger dyrare än Redshift vilket resulterar i att Hadoop väljs minst före Redshift.
14. När det gäller datalastning har Hadoop också varit bakom Redshift i termer om systemet tar timmar för att ladda data från lagringsutrymmet i sitt filbehandlingssystem.
15..Hadoop kan användas för lågkostnadslagring, dataarkivering, dataljöer, datalagring och dataanalys medan Redshift tillhör datalagerfunktioner vilket gör att användningen av flera ändamål begränsas.
16.Hadoop-plattformen ger stöd till olika externa leverantörer och egna Apache-projekt som Storm, Spark, Kafka, Solr etc., och på andra sidan har Redshift begränsat integrationsstöd med sina enda Amazon-produkter
Hadoop vs Redshift jämförelsetabell
| GRUND FÖR
JÄMFÖRELSE | Hadoop | RÖDFÖRSKJUTNING |
| Tillgänglighet | Open Source Framework av Apache Projects | Prissatta tjänster tillhandahålls av Amazon |
| Genomförande | Tillhandahålls av Hortonworks och Cloudera-leverantörer etc., | Utvecklad och tillhandahållen av Amazon |
| Prestanda | Hadoop MapReduce-jobb är långsammare | Redshift presterar snabbare än Hadoop-klustret |
| skalbarhet | Begränsningar i skalbarhet | Lätt enkelt ned / uppskattas enligt krav |
| Prissättning | Kostar $ 200 per månad för att köra frågor | Priset beror på servern och billigare än Hadoop
Till exempel: 20 $ / månad |
| Hastighet | Snabbare men långsammare jämfört med Redshift | 10 gånger snabbare än Hadoop |
| Fråghastighet | Det tar 1491 sekunder att köra 1, 2 TB data | 155 sekunder för att köra 1, 2 TB data |
| Dataintegration | Flexibel med lokalt filsystem och vilken databas som helst | Kan bara ladda data från Amazon S3 eller DynamoDB |
| Dataformat | Alla dataformat stöds | Strikt i dataformat som CSV-filformat |
| Enkel användning | Komplexa och svårare att hantera administrationsaktiviteter | Automatisk säkerhetskopiering och datalageradministration |
Slutsats - Hadoop vs Redshift
Det sista uttalandet för att avsluta den stora vinnaren i denna jämförelse är Redshift som vinner i fråga om enkel drift, underhåll och produktivitet medan Hadoop saknar prestandeskalbarhet och tjänsterna med den enda fördelen med enkel integration med verktyg från tredje part. och produkter. Redshift har nyligen utvecklats med enorm tillväxt och acceptans av många kunder och kunder på grund av dess höga tillgänglighet och mindre kostnad för verksamheten jämfört med Hadoop gör det mer och mer populärt. Men hittills har de flesta av de befintliga Fortune 1000-företagen använt Hadoop-plattformar i sina arkitekturer för att hantera kunddata.
I de flesta fall har RedShift varit det bästa valet att överväga för affärsändamål av en klient eller kund för att hantera de stora och känsliga uppgifterna från finansiella institutioner eller offentliga uppgifter med större dataintegritet och säkerhet.
Bortsett från detta har Hadoop sina egna fördelar med öppen källkodsprojekt och hade funnits i många år också att de befintliga systemen byts ut som en kostnadsförfarande process. Produkten bör äntligen väljas utifrån kravet och flexibiliteten snarare än prissättning eller popularitet baserat på de drivna affärsbehoven.
Rekommenderad artikel:
Detta har varit en guide till Hadoop vs Redshift, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Hadoop vs Hive - Ta reda på de bästa skillnaderna
- HADOOP vs RDBMS | Vet de 12 användbara skillnaderna
- Apache Hadoop vs Apache Spark | Topp 10 jämförelser du måste känna till!
- Big Data vs Data Science - Hur skiljer de sig?
- Guide om Hadoop vs Spark
- Topp 4 leverantörer av molnhotell med funktioner