
Introduktion till R CSV-filer
CSV-filer används ofta för att lagra informationen i tabellformat där varje rad är datapost. För att kunna läsa, skriva eller manipulera data i R måste vi ha vissa data tillgängliga hos oss. Data kan hittas på internet eller kan samlas in från olika källor, t.ex. undersökningar. Med R kan man läsa, skriva och redigera data som lagras i en extern miljö. R kan läsa och skriva data från olika format som XML, CSV och Excel. I den här artikeln kommer vi att se hur R kan användas för att läsa, skriva och utföra olika operationer på CSV-filer.
Skapar CSV-fil i R
I det här avsnittet ser vi hur en dataram kan skapas och exporteras till CSV-filen i R. I den första kommer vi att skapa en dataram som består av variabler medarbetare och respektive lön.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
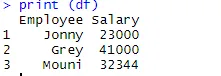
När dataramen har skapats är det dags att vi använder R: s exportfunktion för att skapa CSV-fil i R. För att exportera dataramen till CSV kan vi använda koden nedan.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
I ovanstående kodrad har vi tillhandahållit en sökkatalog för vår datafame och lagrat dataframe i CSV-format. I ovanstående fall sparades CSV-filen på mitt personliga skrivbord. Den här specifika filen kommer att användas i vår handledning för att utföra flera operationer.
Läser CSV-filer i R
När vi utför analyser med R krävs det i många fall att läsa data från CSV-filen. R är mycket tillförlitligt när du läser CSV-filer. I exemplet ovan har vi skapat filen, som vi kommer att använda för att läsa med kommandot read.csv. Nedan är exemplet för att göra det i R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Ovanstående kommando läser filen Employee.csv som är tillgänglig på skrivbordet och visar den i R studio. Header-kommando innebär att rubriken görs tillgänglig för datasatsen och september-kommandot innebär att data är separerade med kommatecken.
Skriv CSV-filer i R
Att skriva till CSV-fil är en av de mest användbara funktioner som finns tillgängliga i R för en dataanalytiker. Detta kan användas för att skriva en redigerad CSV-fil till en ny CSV-fil för att analysera data. Writ.csv-kommandot används för att skriva filen till CSV.
I nedanstående kod df i dataramen där våra data finns tillgängliga används append för att specificera att den nya filen skapas i stället för att lägga till eller skriva över i den gamla filen. Lägg till falskt antyder att en ny CSV-fil skapas. Sep representerar fältet separerat med komma.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-verksamhet
CSV-operationer måste inspektera uppgifterna när de har laddats in i systemet. R har flera inbyggda funktioner för att verifiera och inspektera data. Dessa operationer ger fullständig information om datasatsen.
En av de mest använda kommandona är en sammanfattning.
> summary(df)
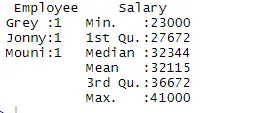
Sammanfattningskommandot ger oss kolumnvis statistik. Den numeriska variabeln beskrivs på ett statistiskt sätt som inkluderar statistiska resultat såsom medelvärde, min, median och max. I exemplet ovan är två variabler som är anställd och lön segregerade och statistik för den numeriska variabeln som är lön visas för oss.
Kommando View () används för att öppna datasatsen i en annan flik och verifiera det manuellt.
> View(df)

Str-funktionen kommer att ge användare mer information om kolumnen i datasatsen. I exemplet nedan kan vi se att medarbetarvariabeln har Faktor som datatyp och Lönevariabeln har int (heltal) som datatyp.
> str(df)

I många fall måste vi se det totala antalet rader som finns tillgängliga för det stora datasettet, för vilket vi kan använda kommandot nrow (). Se exemplet nedan.
> # to show the total number of rows in the dataset
> nrow(df)

På liknande sätt för att visa det totala antalet kolumner kan vi använda kommandot ncol ()
> ncol(df)

R tillåter oss att visa önskat antal rader med hjälp av kommandot nedan. När deras n antal rader finns tillgängliga i datauppsättningen kan vi ange raderna som ska visas.
> # to display first 2 rows of the data
> df(1:2, )

Datahantering utförs på det stora datasettet. För att illustrera har jag laddat ner NI-postnummer med öppen källkod från internet.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
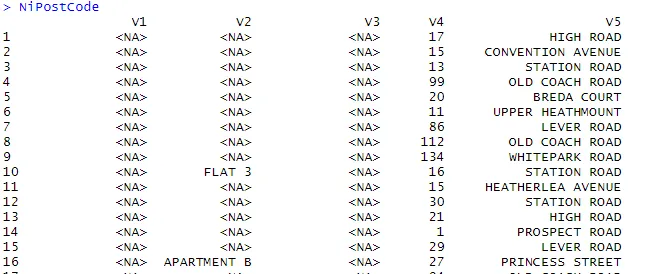
I ovanstående datauppsättning kan vi se rubriknamnen saknas och det finns många nollvärden närvarande. Datasättet måste rengöras för att göra det klart för analys. I nästa steg kommer rubrikerna att namnges i enlighet därmed.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Låt oss nu räkna antalet saknade värden i dataframe och ta bort dem därefter.
> # count of all missing values
> table(is.na (NiPostCode))

Från kommandot ovan kan vi se det totala antalet tomma eller NA i dataframe är nära 5445148. Att ta bort alla nollvärden kommer att leda till förlust av den enorma mängden data, varför det är klokt att ta bort kolumnerna där mer än hälften av 50% av data saknas.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Slutsats
I denna handledning har vi sett hur CSV-filer kan skapas, läsas och bifogas med hjälp av operationer i R. Vi har lärt oss hur man skapar ett nytt datasats i R och importerar dem sedan till CSV-format. Vi har vidare sett flera operationer som att byta namn på rubrik och räkna antalet rader och kolumner.
Rekommenderade artiklar
Detta är en guide till R CSV-filer. Här diskuterar vi skapande, läsning och skrivning av CSV-fil i R med CSV-operationer. Du kan också titta på följande artikel för att lära dig mer -
- JSON vs CSV
- Data Mining Process
- Karriärer inom Data Analytics
- Excel vs CSV