
Introduktion till Hive Group av
Gruppera enligt namnet antyder kommer det att gruppera posten som uppfyller vissa kriterier. I den här artikeln kommer vi att titta på gruppen efter HIVE. I äldre RDBMS som MySQL, SQL, etc, är grupp efter en av de äldsta klausuler som används. Nu har det hittat sin plats på ett liknande sätt i filbaserad datalagring som känd är HIVE.
Vi vet att Hive har överträffat många äldre RDBMS för att hantera enorma data utan att ett öre har spenderats på leverantörer för att underhålla databaser och servrar. Vi behöver bara konfigurera HDFS för att hantera bikupa. I allmänhet flyttar vi till tabeller eftersom slutanvändaren kan tolka från dess struktur och kan fråga efter eftersom filer kommer att vara klumpiga för dem. Men vi var tvungna att göra detta genom att betala leverantörerna för att tillhandahålla servrar och underhålla våra data i form av tabeller. Så Hive tillhandahåller den kostnadseffektiva mekanismen där den tar fördelen med filbaserade system (hur hive sparar sina data) såväl som tabeller (tabellstruktur för slutanvändarna att fråga efter).
Grupp av
Gruppera med hjälp av de definierade kolumnerna från Hive-tabellen för att gruppera data. Tänk på att du har en tabell med folkräkningsdata från varje stad i alla stater där stadens namn och statens namn är en av kolumnerna. Nu i frågan, om vi grupperar efter stater kommer alla data från olika städer i en viss stat att grupperas ihop och man kan enkelt visualisera uppgifterna bättre nu innan det sätt på vilket gruppen användes.
Syntax av Hive Group av
Gruppens allmänna syntax enligt klausul är som nedan:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
eller för enklare frågor,
from Group By
Select department, count(*) from the university.college Group By department;
Här hänvisar institutionen till en av kolumnerna i kollegietabellen som finns i universitetsdatabasen och dess värde är olika inom avdelningar som konst, matematik, teknik, etc. Låt oss nu se några exempel för att visa grupp efter.
Jag har skapat ett exempel på tabellen deck_of_cards för att demonstrera gruppen efter. Dess skapa tabelluttalande är som följer:
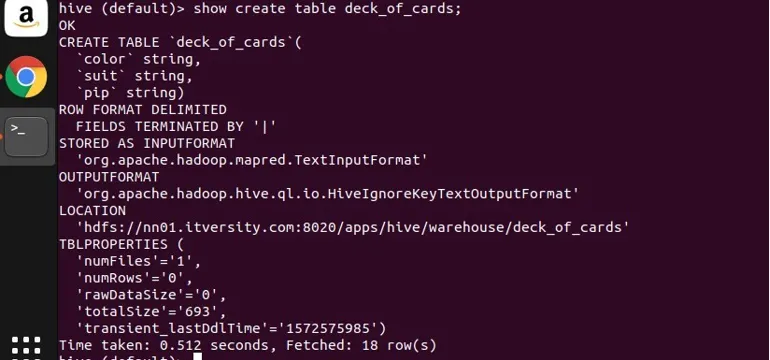
du kan se ovanifrån att den har tre strängkolumner färg, färg och pip. Låt mig skriva en fråga för att gruppera informationen efter deras färg och få antalet.
select color, count(*) from deck_of_cards group by color;
Hive tar i princip ovanstående fråga för att konvertera den till kartminskningsprogrammet genom att generera motsvarande java-kod och jar-fil och sedan kör. Den här processen kan ta lite tid men den kan definitivt hantera stora data jämfört med traditionell RDBMS. Se nedanstående skärmdump med den detaljerade loggen för att utföra frågan ovan.
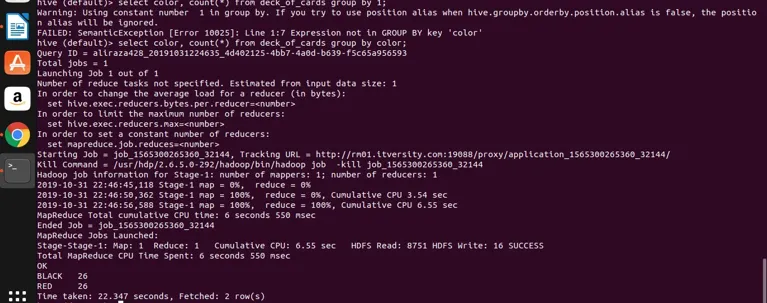
du kan se att BLACK är 26 och RED är 26.
låt oss nu tillämpa gruppering på två kolumner (färg och färg och få gruppantal) och se resultatet nedan.
Select color, suit, count(*) from deck_of_cards group by color, suit
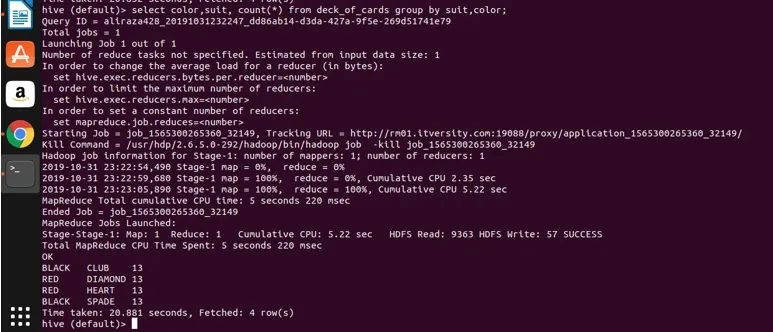
I princip finns det fyra distinkta grupper ovanför Club, Spade som har färg svart och Diamond och hjärta som är färgröda.
Lagra resultatet från grupp efter orsak i en annan tabell
Hive ger också som alla andra RDBMS funktionen att infoga data med skapa tabelluttalanden. Låt oss titta på att lagra resultatet från ett valt uttryck med en grupp genom i en annan tabell. Låt mig använda ovanstående fråga där jag har använt två kolumner i grupp efter.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
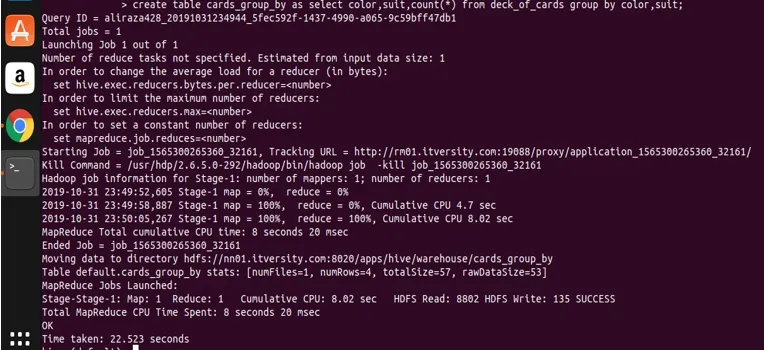
låt oss nu fråga i den skapade tabellen för att se och validera data.

Låt oss nu begränsa resultatet av gruppen genom att använda klausul. Som visas i den generiska syntaxen kan vi tillämpa begränsningar på gruppen genom att använda. Här använder jag tabellen ordser_items och strukturen är som följer av beskrivningen.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
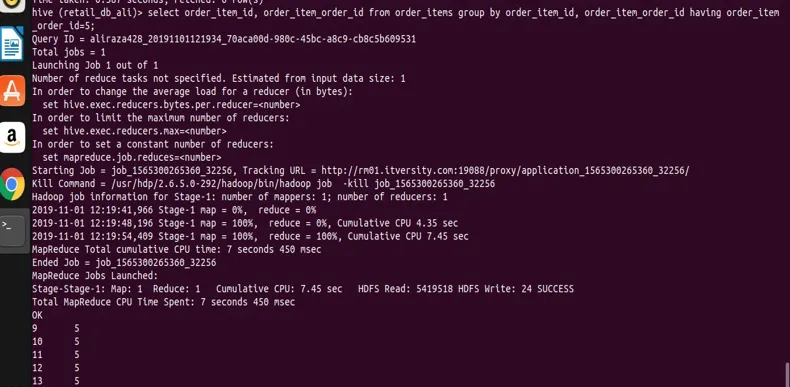
från resultatet kan du se skärmdumpen att vi bara har poster med order_item_order_id värde 5.
Grupp efter Tillsammans med ärende
Låt oss nu titta på lite komplexa frågor som involverar CASE-uttalanden med gruppen av. Vi kommer att tillämpa detta på tabellen order_items. Nedan ser vi att vi kan kategorisera de icke-aggregerande kolumnerna på vilka vi inte kan tillämpa gruppen direkt genom klausul.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
låt oss köra det i bikupan för resultat
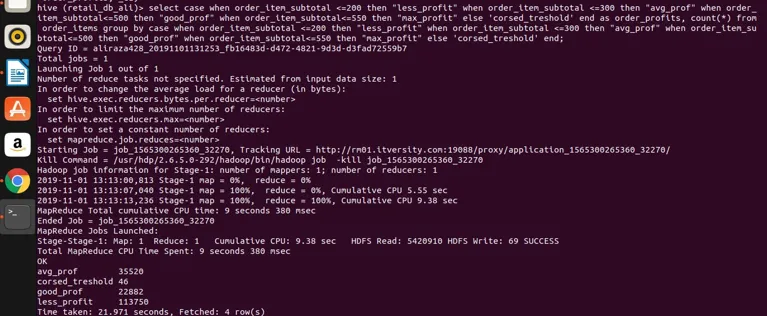
Slutsats - Hive Group av
så vi kan se att vi har grupperat order_item_subtotal i fyra olika kategorier (om du noterar att order_item_subtotal är en icke-aggregerande kolumn och direkt grupp av inte kan tillämpas på den) och vi har grupperat dem tillsammans och fått deras räkningar också för värdena som tillfredsställer intervallet enligt definitionen i det valda uttrycket. Här är den enkla regeln om kolumnen är icke-aggregerande och vårt utvalda uttryck är komplexa, oavsett vad som finns i det markerade uttrycket som också bör finnas i gruppen med klausuluttryck. Så vi har sett hur en berömd klausul RDBMS klausulgrupp av också kan tillämpas på Hive utan några begränsningar. Det kan tillämpas på enkla utvalda uttryck. Samla och filtrera uttryck, anslut uttryck och komplexa CASE-uttryck också.
Rekommenderade artiklar
Detta är en guide till Hive Group By. Här diskuterar vi gruppen efter, syntax, exempel på bikupa-gruppen med olika förutsättningar och implementering. Du kan också titta på följande artiklar för att lära dig mer -
- Går med i Hive
- Vad är en bikupa?
- Hive Arkitektur
- Hive-funktion
- Hive Order by
- Hiveinstallation
- Topp 6 typer av sammanfogningar i MySQL med exempel