

Vad är Kafka?
För att förstå Kafka är det bättre att förstå vad "Streambehandling" -teknologi är. 'Streambehandling är en teknik där en användare kan fråga en kontinuerlig dataström inom en mikrotidsram för att bättre förstå underliggande förhållanden.
Ett realtidsscenario - föreställ dig om din temperatursensor skickar data som du kan fråga och få en varning efter att en fryspunkt har mottagits. Denna datafråga kan göras i mikrosekunder.
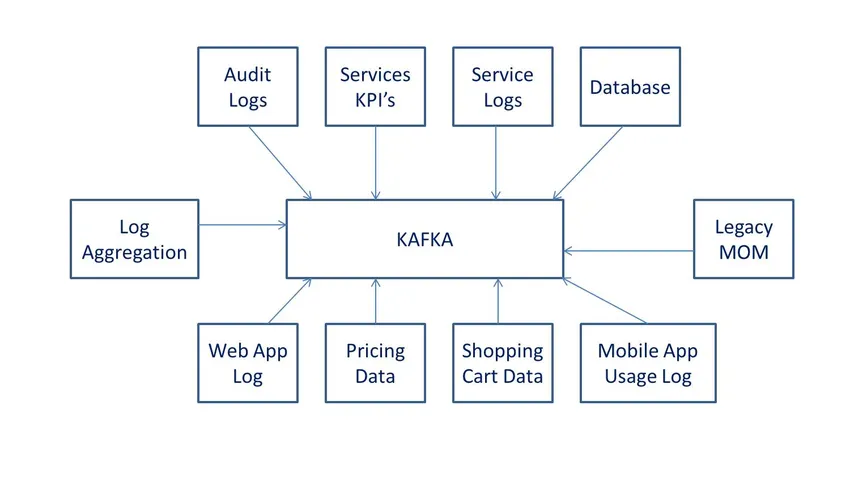
Definitioner
enligt Wiki är det programvara för öppen källkod för databehandling. Det utvecklades av LinkedIn och donerades senare till Apache-programvaran.
Förstå Kafka
Tillväxten exploderar exponentiellt. Låt oss se några fakta och statistik för att bättre understryka vår tanke. Det åtnjuter den främsta preferensen av mer än en tredjedel av Fortune 500 över hela världen. Denna distribution delas av reseföretag, telekomjättar, banker och flera andra. LinkedIn, Microsoft och Netflix behandlar fyra komma-meddelanden om dagen med Kafka (nästan motsvarar 1 000 000 000 000).
Det används för realtidsströmmar av data, för att samla in big data eller för att göra realtidsanalys (eller båda). Kafka används med mikroservices i minnet för att ge hållbarhet och det kan användas för att mata händelser till CEP (komplexa händelseströmningssystem) och IoT / IFTTT-automatiseringssystem.
Hur fungerar Kafka så enkelt?
Drivs av enkelhet är det rätta sättet att definiera prestanda. Det är lätt att ta reda på hur Kafka fungerar så enkelt från installation och användning. Denna ökade prestanda i beteende är dedikerad till dess stabilitet, dess tillförlitlighet för pålitlig hållbarhet, med sin flexibla inbyggda förmåga att publicera eller prenumerera eller underhålla kö. Detta är mycket viktigt att ha om du behöver ta itu med N - antal klientgrupper, om du måste visa en robust replikering på marknaden, som syftar till att ge dina kunder en konsekvent strategi (dvs. Kafka ämnespartition). Ett avgörande beteende hos Kafka som skiljer det från sina konkurrenter är dess kompatibilitet med system med dataströmmar - dess process och gör att dessa system kan aggregera, transformera och ladda andra butiker för bekvämlighetsarbetet. ”Alla ovannämnda fakta skulle inte vara möjliga om Kafka var långsam”. Dess exceptionella prestanda gör detta möjligt.
Med ytterligare tillägg till det enkla arbetet med Kafka måste vi gå till ”OS-nivå”. Låt oss hitta hur saker fungerar för Kafka på OS-nivå -
- Det förlitar sig på OS-kärnor för att flytta data snabbare och fungerar på principen om nollkopiering.
- Det tillåter dataposter att samlas i bitar som kan ses från filsystem (aka Kafka ämneslogg) till konsumenter.
- Möjligheten att batchdata ger en effektiv datakomprimering med I / O-latensminskning.
- Det har förmågan att skala horisontellt via skärning. Det kan skärpa en titellogg till hundratals partitioner till tusentals. Detta gör att den enkelt kan hantera den enorma arbetsbelastningen.
Vad kan du göra med Kafka?
Om ditt företag leker med enorma uppsättningar data regelbundet behöver du Kafka. Det finns en lång lista över företag som använder den.
- LinkedIn använder för att spåra data och operativa mätvärden.
- Twitter för att tillhandahålla infrastruktur för strömbearbetning.
Det finns en lång lista över företag från Uber till Spotify och Goldman Sachs till Cisco.
fördelar
- Hög kapacitet: Den kan enkelt hantera en stor mängd data när generering med hög hastighet är en exceptionell fördel till förmån för Kafka. Den här applikationen saknar enorm hårdvara. Med kapacitet att stödja meddelandetillförsel med en frekvens av tusentals meddelanden per sekund.
- Low Latency: Low latency hantering av denna meddelandegenerering med hög volym.
- Fel-tolerans: Den här funktionen är mycket användbar, den har en inneboende förmåga att begränsas av nod inbyggd i ett kluster.
- Hållbar: den är mycket hållbar i sin drift och är därför varför många MNC: er föredrar att använda Kafka. Med tanke på hållbarhet i operationer kan meddelandena inte gå vilse på lång sikt.
Erforderliga färdigheter
Det finns inget speciellt krav för att vara en Kafka-professional. Men vi har understrukit några strömmar och proffs -
- Utvecklare som villigt göra en karriär i Big Data-strömmen och vill påskynda karriären där.
- Testprofessionell har ett bra utbud i Kafka när det gäller kö- och meddelandesystem
- Arkitekter - eftersom allt behöver vissa ramar och denna ram kan uppdateras då och då. Big Data-arkitekter skulle hitta Kafka som en bra karriärinvestering.
- Projektledare behövs om ovanstående proffs finns för bättre hantering av resurserna. Så högre positioner finns också tillgängliga för managementpersonal inom området Kafka.
Varför använda Kafka?
I syfte att spåra och manipulera dem enligt affärsbehov föredras Kafka världen över. Det ger möjlighet att strömma data i realtid med realtidsanalyser. Den är snabb, skalbar och hållbar och utformad som feltolerans. Det finns flera användningsfall på webben där du kan se varför JMS, RabbitMQ och AMQP inte ens anses arbeta med eftersom behovet är att driva enorm volym och lyhördhet.
Den har hög genomströmning, pålitlig installation med replikationsegenskaper som gör det till ett föredraget val att arbeta med IoT-sensorer.
Kompatibilitet är en annan anledning till att använda den och gjorde det acceptabelt över hela världen. Det kan enkelt konfigureras för att fungera med nedanstående applikation. Denna kombination är mycket viktig för många företag att växa affärer och överleva (eftersom det sparar tid och pengar).
- Flume
- Spark Streaming
- HBase
- Spark för intag, bearbetning och analys av data i realtid.
- Den är van vid att mata Hadoop BigData
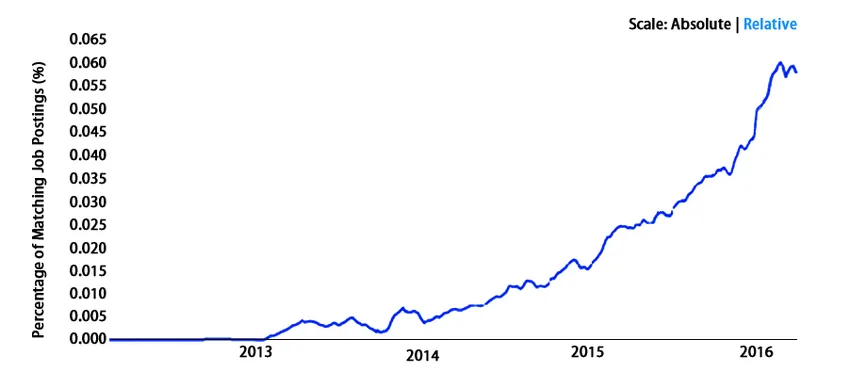
Omfattning
Det går bra över hela världen. Vi säger inte detta snarare statistik. Låt oss ta en titt -
Lönestatistik för Kafka-proffs - PayScale
- Software Engineer - 109 825 dollar
- Data Engineer - 109 580 $
- Utvecklare - 81 182 dollar
- Senior Data Engineer - $ 127, 836
Slutsats
För närvarande har Kafka blivit den de facto-standarden när det gäller realtidsdataanalys med högsta precision i mikrosekunder. Vi har presenterat våra insikter när det gäller data och detaljer till stöd för Kafka-teknologier. Det finns flera stora företag som utnyttjar data dagligen, för att göra det behöver de proffs för att utnyttja dessa enorma datamängder. Med Kafka kan man vara säker på att leda sin karriär i en BigData-analys
Rekommenderade artiklar
Detta har varit en guide till Vad är Kafka. Här diskuterade vi arbetet, omfattningen, karriärstillväxten och fördelarna med Kafka. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Vad är Apache?
- Vad är Big data och Hadoop?
- Vad är Azure?
- Vad är Big Data Technology?
- Kafka vs Spark | Topp 5 skillnader
- Översikt och toppapplikationer för Kafka
- Kafka vs Kinesis | 5 skillnader med infographics